
Data Engineer Things Newsletter - Data Pulse Edition (Feb 2026)
Data Movement at Netflix, Uber's Trillion-Record Lake, AI Skills for Agents and Building Your Brand in Data Engineering





Hello Folks,
Great to connect with you through this month’s newsletter! I hope the resolutions you set at the start of the year are still going strong.
I'm writing this from Coimbatore, India, where the cooler winter mornings are slowly transitioning to warmer and brighter days. There's something I love about this time of year here - clear skies, fresh energy in the air, and that sense of momentum building as the season shifts.
That momentum reminds me of data engineering. The big transformations rarely happen overnight, but every new tool we explore, every system we scale, every challenge we solve it all adds up over time. It’s that steady, consistent work that fuels real progress. And through it all, we're building something meaningful: data systems people can actually rely on.
Outside of work, I enjoy reading, travelling, and watching movies - small ways to recharge and stay curious. In many ways, this community offers the same: a space to learn from each other and continue growing together.
This edition is packed with ideas and resources from across the community. I hope you find something here that sparks a new idea or gives you a fresh perspective.
Happy reading, and thank you for being on this journey with us.
- Sri
📚 Data Pulse
Netflix: Simplify Data Movement using Data Bridge
📖 Topic: Data Ingestion
🧠 Level: Intermediate
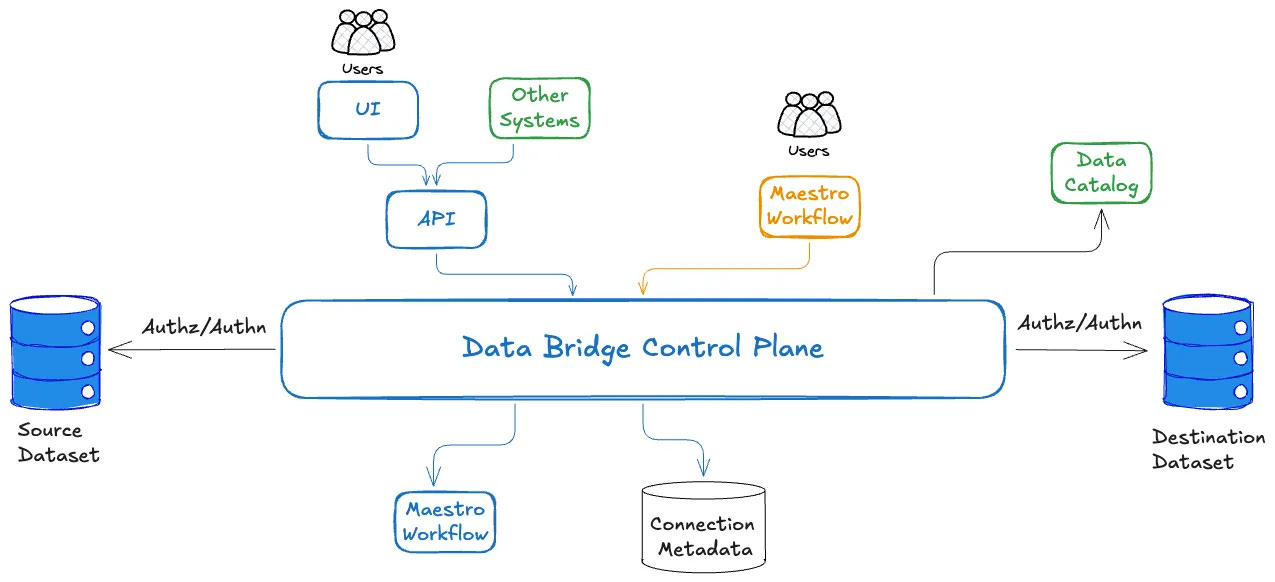
Summary: Netflix introduces Data Bridge, a unified control plane that standardizes how data is moved across its vast ecosystem of data stores. Instead of teams building case-specific/custom pipelines for every new data movement use case, Data Bridge abstracts the implementation details of how it is moved from why and what data needs to be moved. Data engineers declare their intent once, and the platform handles routing, execution, and operational concerns behind the scenes.
💡 Why is this relevant for DEs?
Platform over Pipelines: It helps data engineers move from building siloed data movement pipelines to designing a centralized orchestration layer. This enables reuse, governance, and delivery at scale, rather than reinventing the wheel for every use case.
Self-Service: New teams and data stores can plug into the system without reinventing ingestion or replication patterns.
Operational Consistency: It has built-in handling for retries, monitoring, and failure management, so it ensures consistent reliability across all data transfers.
Reduced Fragmentation: It consolidates fragmented data movement systems into one standardized approach.
Advice to Start a Blog
📖 Topic: Brand Building
🧠 Level: All levels
Summary: David Robinson argues that aspiring data scientists (note: valid for DEs as well) should start blogging as a key strategy for breaking into the field. Rather than just completing courses, candidates should publicly share analyses, tutorials, and projects on topics they find interesting. Blogging serves three critical purposes: it provides hands-on practice with real-world data analysis and communication skills; it creates a portfolio that demonstrates capabilities to potential employers better than resumes alone; and it generates feedback from the community while helping build a professional network. Robinson emphasizes that posts don’t need to be perfect! Sharing any public work is valuable, and even simple explanations of concepts you’ve mastered can resonate with audiences.
💡 Why is this relevant for DEs?
Portfolio & Personal Brand: A blog provides concrete examples of your work that make interviews and applications more compelling than resumes alone, while establishing you as a thought leader and building a professional network that creates unexpected job opportunities.
Practice with Purpose: Blogging forces you to work with real-world messy data and communicate findings, developing the exact skills employers need while revealing knowledge gaps and hidden strengths through community feedback.
LinkedIn: Engineering the Job Ingestion System at Scale
📖 Topic: Data Platform
🧠 Level: Intermediate
Summary: LinkedIn shares how they built a large-scale job ingestion system capable of processing millions of job postings from diverse sources reliably and efficiently. Instead of relying on fragmented ingestion workflows, LinkedIn designed a unified, scalable ingestion architecture that standardizes parsing, validation, enrichment, and indexing of job data. The system focuses on handling high-volume, heterogeneous inputs while ensuring data quality, low latency, and operational stability across downstream search and recommendation systems.

💡 Why is this relevant for DEs?
Scalable Ingestion Architecture: Instead of building ingestion logic per partner or per feed, LinkedIn invested in a standardized ingestion framework. This represents the move from ad hoc pipelines to platform engineering. The architecture supports horizontal scaling and distributed processing, allowing millions of records to be processed per day without degrading performance or increasing operational overhead.
Data Quality at Ingestion Layer: Schema validation, normalization, and enrichment happen early in the pipeline, reducing downstream correction cycles and improving the reliability of search and recommendation systems.
Handling Heterogeneous Sources: In real-world systems, inputs from different sources rarely follow a single format. A strong ingestion framework abstracts this variability and converts it into a unified internal schema. For DEs, this means designing flexible parses, schema evolution strategies, and metadata-driven mappings that can scale without rewriting pipelines for every new source.
Operational Resilience: The architecture is designed to manage failures, retries, and backpressure effectively, ensuring stability even during traffic spikes.
Uber: Engineering for Trillion-Record-Scale Data Lake Operations
📖 Topic: Data Lake
🧠 Level: Beginner
Summary: Uber shares how they adopted Apache Hudi to solve large-scale data lake challenges such as late-arriving data, incremental processing, and inconsistent batch pipelines. Hudi adds transactional semantics, upserts, and time travel capabilities on top of cloud object storage, enabling Uber to treat their data lake more like a database while retaining scalability.
Instead of rebuilding datasets from scratch, Uber uses Hudi’s incremental ingestion and record-level updates to efficiently manage continuously evolving datasets across thousands of pipelines.
💡 Why is this relevant for DEs?
Reliable Data Lakes (Lakehouse Foundations): Hudi introduces ACID transactions, schema evolution, and rollback support to the data lakes; it helps data engineers safely handle late data, reprocessing, and failures without breaking downstream pipelines.
Scales with Streaming and Batch: Hudi supports both streaming ingestion and batch workloads, helping teams unify real-time and batch pipelines under a single data store.
Incremental Pipelines: It allows pipelines to process just the new or updated data since the previous run, instead of scanning terabytes of data in each run.
Indexing and Fast Upserts: It allows data engineers to perform fast row-level updates across hundreds of partitions and billions of records.
⚒️ Workshop: Getting Started with Protobuf APIs

If schema evolution keeps biting you in production (breaking changes, inconsistent validation, tooling sprawl), this Protobuf workshop is worth your time. You will learn:
How to adopt Protobuf to prevent breaking changes and evolve schemas safely across teams and languages
How to use Protobuf in event streaming and data pipelines for better data quality
Best practices for designing real-world APIs
👉 Sign up for the workshop HERE.
(This message is sponsored by Buf)
💎 Open Source Gems
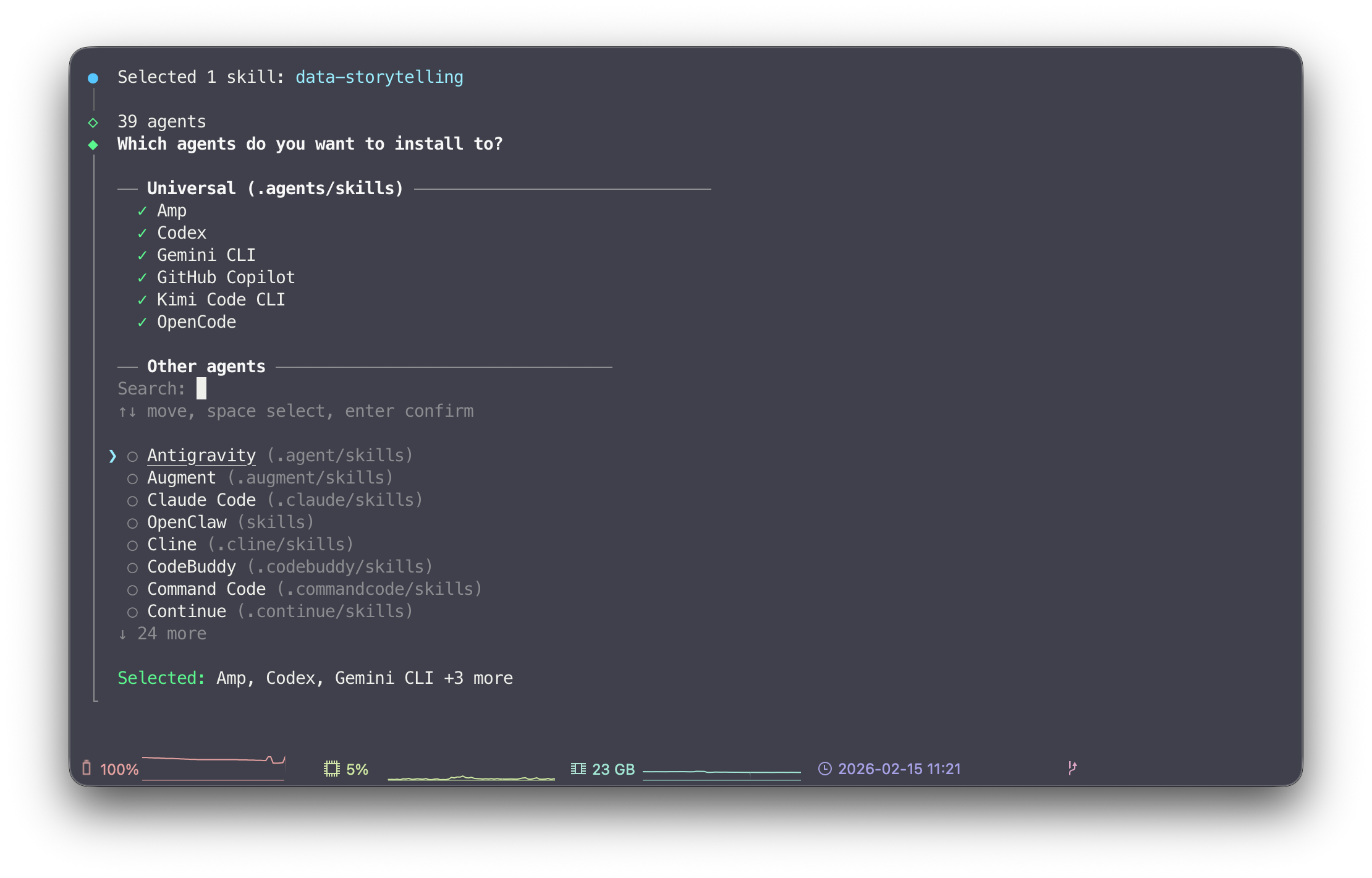
skills CLI for the open agent skills ecosystem
Skills are reusable capabilities for AI agents. They provide procedural knowledge that helps agents accomplish specific tasks more effectively. skills is an open-source CLI for installing and managing skill packages for agents.
Together with skills.sh, a directory and leaderboard for skill packages, it allows you to easily install and manage skills for all common AI tools like Claude Code, Codex, Cursor, OpenClaw, Gemini CLI, and many more.
💡 Why is this relevant for DEs?
Using AI to implement data pipelines, or any type of software development, has become the new norm. However, in Data Engineering in particular, we work with highly specialized tools, different versions, and varying best practices. This often leads to significant back and forth when using AI to speed up implementation. Installing skills can help, as they target specific use cases. Tools like Claude Code automatically apply a skill when they determine it fits the use case, which can significantly improve the quality of the output.
🧑💻 Skills for DEs
data-quality-frameworks: Production patterns for implementing data quality with Great Expectations, dbt tests, and data contracts to ensure reliable data pipelines.
brainstorming: Turn ideas into fully formed designs and specs.
dbt-transformation-patterns: Production-ready patterns for dbt.
authoring-dags: Creating and validating Airflow DAGs using best practices.
data-storytelling: Transform raw data into compelling narratives.
And many more.
Github: https://github.com/vercel-labs/skills
💡 DE Tip of the Month
Treat data contracts as non-negotiable in modern pipelines:
As data feeds more dashboards, models, and AI systems, failures are shifting from job failures to correctness. Pipelines run successfully, but silent changes in schema, freshness, or semantics break dashboards, models, and business decisions.
Data contracts help prevent this. They define clear expectations between data producers and consumers so everyone knows what a dataset promises to deliver.
💡 Why it matters now more than ever
AI agents, auto-generated SQL, and self-serve analytics are increasing the number of data consumers without deep context
Faster development with a variety of tools like dbt, Spark, and Flink increases the risk of unintended schema changes.
The cost of bad data is often higher than pipeline downtime.
💡 How to start
Add contracts to your most critical datasets
Enforce them with tests and freshness checks
Make them visible in your metadata catalog
Start small and expand gradually.
Teams that treat data contracts seriously spend less time firefighting and build stronger trust between data producers and consumers.
Let us know what you like the most in the newsletter. See you next time!
Until next time, cheers!
ℹ️ About Data Engineer Things
Data Engineer Things (DET) is a global community built by data engineers for data engineers. Subscribe to the newsletter and follow us on LinkedIn to gain access to exclusive learning resources and networking opportunities, including articles, webinars, meetups, conferences, mentorship, and much more.