
Data Engineer Things Newsletter - Data Pulse Edition (Mar 2026)
OpenAI's P99 latency with 800 million users, Netflix's LLM post training, LinkedIn's exabyte scale clusters, ETL → ECL, and Elements of a modern data strategy





Hello Folks,
Great to connect with you again for another edition! I’m writing this from Philadelphia, where the worst of winter is finally behind us and the days are slowly getting longer and warmer.
Much like the shifting seasons, data engineering itself is in the middle of a transformation. In 2026, it's no longer just about moving and storing data; it's about making data meaningful, trustworthy, and AI-ready. Whether you’re building pipelines, designing data platforms, or enabling AI systems, the common thread is clear that the future of data engineering is as much about context and reliability as it is about movement and scale.
If you’re looking for a place where these conversations are happening in person, check out the Data Engineering Open Forum in San Francisco on April 16th. The agenda is packed with sessions you'll actually want to stay for, and it's a great chance to connect with engineers navigating the same challenges you are.
- Ananda
📚 Data Pulse
Data Engineering After AI: ECL - Extract, Contextualize, Link
📖 Topic: Data & Context Engineering
🧠 Level: Beginner
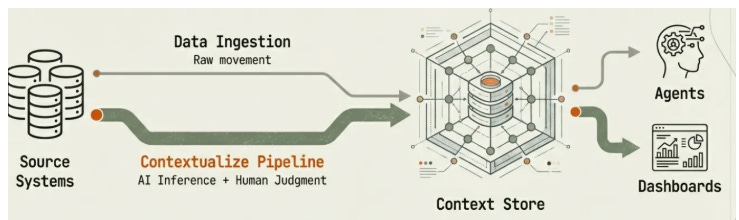
Summary: As AI continues to automate data engineering tasks such as pipeline generation, transformation logic, and schema inference, the core role of data engineers is shifting from moving data to defining and managing its meaning. Traditional ETL architectures focused on data movement, and they often embedded business logic within pipelines, allowing interpretive context to drift as data passed through successive transformations. An alternative framework, ECL (Extract, Contextualize, Link), addresses this gap by emphasizing three stages: extracting reliable data from source systems, enriching it with contextual definitions, and linking entities across systems to preserve coherence.
💡 Why is this relevant for DEs?
Shift in core responsibilities: Data engineers should focus more on designing architectures that preserve and govern the semantic meaning of data across systems.
Need for semantic and governance infrastructure: With ECL, data engineers need to build and manage data contracts, lineage systems, and context stores that ensure data definitions remain consistent, versioned, and trustworthy as data moves through multiple transformation layers.
Emergence of a new role: The discipline is evolving from pipeline engineering to “context architect,” where data engineers design the contextual frameworks that allow AI systems and downstream applications to interpret and use data reliably.
OpenAI: Scaling to 800 Million Users With Postgres - P99 latency
📖 Topic: Databases
🧠 Level: Intermediate
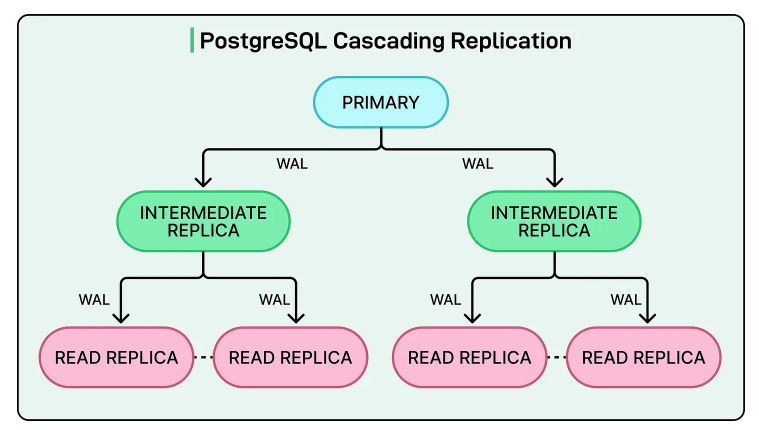
Summary: OpenAI scaled PostgreSQL to support over 800 million ChatGPT users using a single primary database with dozens of read replicas, skipping complex sharding entirely. By focusing on reducing primary writer load, optimizing queries and connections, and preventing cascading failures, they achieved low double-digit millisecond latency and 99.999% availability.
💡 Why is this relevant for DEs?
Optimize before adding complexity: OpenAI showed that tuning PostgreSQL for query optimization, caching, and connection pooling can delay or eliminate the need for sharding and distributed systems.
Design for your actual workload: ChatGPT is largely read-heavy, so read replicas and caching worked. Match your architecture to what your system actually does, not to generic best practices.
Reliability is key: Tools like PgBouncer, rate limiting, and workload isolation show that modern data engineering is as much about keeping systems stable as it is about building pipelines.
Netflix: Scaling LLM Post-Training
📖 Topic: Data Engineering & AI
🧠 Level: Intermediate
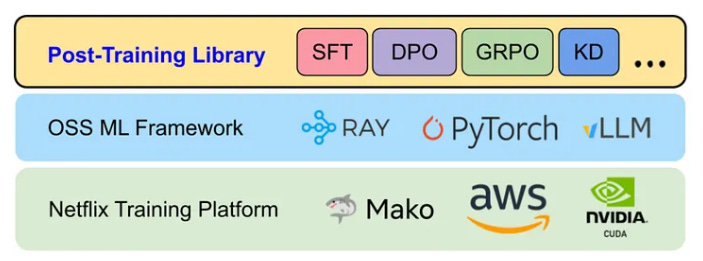
Summary: Netflix built an LLM post-training framework to scale the adaptation of foundation models for production use cases such as recommendations, personalization, and search. Pre-trained models must be adapted to understand Netflix’s catalog and user behavior, but doing this at Netflix scale, with massive data pipelines and distributed GPU clusters, is a major engineering challenge. The framework, built on their ML platform Mako using PyTorch, Ray, and vLLM, enables techniques like fine-tuning, reinforcement learning, preference optimization, and knowledge distillation. The framework is organized around four pillars: data, model, compute, and workflow, providing a unified way to manage datasets, shard models, orchestrate GPUs, and run multi-stage training pipelines.
💡 Why is this relevant for DEs?
Data pipelines are foundational to LLM training: Post-training workflows depend on well-prepared data curated datasets, proper tokenization, and efficient streaming to distributed training systems. Data engineers own the pipelines that handle all of this, from selecting and transforming domain-specific data.
LLM systems require scalable data infrastructure: Netflix’s framework underscores the need for distributed workflows to coordinate across GPUs, storage, and orchestration layers. Data engineers are central to building the plumbing that moves, batches, and serves data reliably for both training and inference.
LinkedIn: Maintaining exabyte-scale Hadoop clusters
📖 Topic: Data Infrastructure
🧠 Level: Advanced
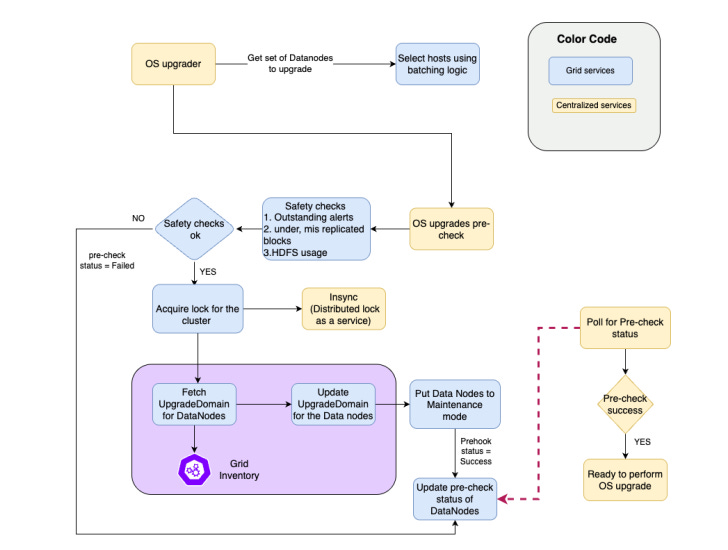
Summary: LinkedIn re-engineered the block placement strategy in Apache Hadoop’s HDFS to support exabyte-scale clusters storing about 5 exabytes of data and 10 billion objects while maintaining 99.99% availability. As clusters expanded to thousands of nodes, the default rack-based replication policy caused heavy overhead during maintenance because nodes had to replicate large volumes of data before going offline.
To address this, LinkedIn introduced upgrade domains, logical groupings of datanodes that distribute replicas across broader failure boundaries than racks. By updating the block placement policy without disrupting production traffic, LinkedIn eliminated large-scale replication during maintenance, reducing network congestion, speeding up upgrades, and allowing maintenance on up to 4.5% of datanodes per day while maintaining performance and reliability.
💡 Why is this relevant for DEs?
Data reliability and availability at massive scale: Data engineers working with distributed storage systems such as Apache Hadoop must design architectures that ensure high data availability, redundancy, and fault tolerance, even when clusters contain thousands of nodes and exabytes of data.
Operational scalability is a core data engineering challenge: As data platforms grow, routine operations such as hardware upgrades, patching, and cluster maintenance must be redesigned to avoid massive data movement or downtime, highlighting the need for an architecture that scales operationally as well as technically.
Elements of a Modern Data Strategy
📖 Topic: Data Strategy
🧠 Level: Intermediate
Summary: A modern data strategy is what separates organizations that talk about data from those that actually drive results with it. It aligns people, processes, and technology across five foundational pillars.
Tying every data initiative directly to business outcomes through deep stakeholder engagement.
Selecting a tech stack that scales and works as a cohesive ecosystem.
Embedding governance for high-quality data and trust.
Investing in talent with clear roles and continuous enablement.
Laying out a prioritized roadmap that balances quick wins with long-term transformation.
Without this foundation, organizations end up with fragmented data, slow decision-making, shelfware investments, and an inability to capitalize on AI and automation when it matters most.
💡 Why is this relevant for DEs?
The data stack, pipelines, storage architecture, and integration layers defined in a data strategy are largely designed and implemented by data engineers, making them central to turning strategy into working systems.
Data engineers operationalize data governance, lineage, access controls, and reliable data pipelines, ensuring that data across the organization is trusted, consistent, and usable for analytics and AI.
⚒️ Data Engineering Open Forum 2026

The Data Engineering Open Forum (DEOF) is a community-driven conference featuring in-depth sessions that address the real challenges and innovations in data engineering today. The talks cover a wide variety of topics, including AI Agents, Multimodal data, Data lineage, Data Observability, Semantic layer, and more.
Out of a stacked lineup, the two sessions below caught my eye.
From Manual to Magical: Building AI Agents for ETL Automation by Himanshi Manglunia, Senior Data Engineer @ AWS: This talk demonstrates a production-grade, autonomous ETL system in which AI agents (powered by Kiro and Claude) handle end-to-end pipeline changes.
Inside OpenAI’s Internal AI Data Agent by Bonnie Xu, Staff Software Engineer @ OpenAI: This session provides a look under the hood of OpenAI’s internal data agent, a tool that lets employees turn questions into insights in minutes. Xu unpacks the agent’s core architecture, the multiple layers of context it uses to answer queries, and how the team keeps that context updated with almost zero manual intervention.
📋 Agenda and more details HERE.
👉 RSVP before March 22 to get an exclusive DET community discount (33% off).
💎 Open Source Gems
Cube Core is an open-source semantic layer that lets organizations define metrics, dimensions, and business logic once and reuse them across BI tools, embedded analytics, and AI agents through standard REST, GraphQL, and SQL APIs. It works with all major SQL data sources, Snowflake, Databricks, BigQuery, Postgres, and more, and includes a built-in caching engine for sub-second query performance.
💡 Why is this useful for DEs?
With Cube Core, data engineers define metrics and business logic in one place, and every tool, BI dashboards, applications, and AI agents pull from the same definitions.
Most organizations run multiple BI tools and data platforms. A semantic layer sits between them and provides a single, consistent way to query data, eliminating duplicate logic and unnecessary complexity.
Github: https://github.com/cube-js/cube
💡 DE Tip of the Month
Processing large time-series datasets in dbt
Microbatch incremental models in dbt efficiently process large time-series datasets by splitting transformations into small, time-bounded batches based on an event_time column.
Atomic, idempotent batch execution: Each batch represents a self-contained unit of work that can run independently, be retried if it fails, and even execute in parallel for faster data processing.
Simpler incremental logic: Unlike traditional incremental models that require custom SQL conditions, micro batch automatically determines which batches to run, simplifying model design.
Flexible backfills and failure recovery: Engineers can easily reprocess historical data or retry failed batches by specifying time ranges (--event-time-start and --event-time-end) without rebuilding the entire dataset.
📊 Community Poll
Until next time, cheers!
ℹ️ About Data Engineer Things
Data Engineer Things (DET) is a global community built by data engineers for data engineers. Subscribe to the newsletter and follow us on LinkedIn to gain access to exclusive learning resources and networking opportunities, including articles, webinars, meetups, conferences, mentorship, and much more.
Renaming ETL to ECL feels like a small shift, but it captures something important: the "Link" step is where most data strategies quietly collapse. Organizations invest heavily in Extract and Contextualize — clean pipelines, semantic layers, data contracts — and then assume entities will just... align. They don't. The same customer appears as five records across CRM, billing, and support systems. The same supplier has three different names across procurement and finance.
Without resolving identity across systems, your context layer is built on sand.
What's exciting about the AI era is that it forces this reckoning. You can patch over bad entity resolution in a BI dashboard, but an LLM reasoning over fragmented customer records will confidently hallucinate conclusions.
Great edition — the ECL framing is one worth evangelizing.