
Data Engineer Things Newsletter - Data Pulse Edition (May 2026)
Spotify's coding agents that saved 10 engineering weeks, how Meta encoded tribal knowledge for AI agents, and Pinterest's CDC-to-Iceberg architecture explained





Hello Folks,
Still processing. That’s the honest summary of this past week. I just got back from the Data Innovation Summit 2026 at Kistamässan in Stockholm, and I’m still untangling what I actually learned from and what I enthusiastically nodded at in a hallway.
Two moments keep coming back to me. Dael Williamson from Databricks put it simply: organisations are no longer just adopting AI tools, they’re running fleets of agents that reshape workflows in real time. Build your data foundations now, or get buried later. Then Joe Reis’s masterclass reframed data modeling as a strategic capability, not a dogma and landed two quotes I haven’t stopped thinking about:
“AI amplifies what you know to do at machine speed. It also amplifies what you don’t.”
And:
“Disciplined teams will use AI to move faster with quality. Undisciplined teams will use AI to create technical debt faster.”
That second one hit hard in our governance roundtable.
I’m Chozhan, Head of Data Platform and a passionate Data Engineer. This edition picks up right where DIS2026 left off, a real production story from Spotify on agentic dataset migrations, a fresh benchmark from dbt Labs on Semantic Layer vs. text-to-SQL, a tool-agnostic observability guide, and an honest look at what declining DE job postings are indirectly hinting us. Thanks for being here, let’s dive right in.
– Chozhan
📚 Data Pulse
Next Generation DB Ingestion at Pinterest
📖 Topic: Real-World Streaming & Lakehouse Architecture
🧠 Level: Beginner
Summary: Pinterest’s Logging Platform team replaced a patchwork of batch-oriented, full-table dump pipelines where data latency exceeded 24 hours, with a unified CDC-based framework built on Debezium, Kafka, Flink, Spark, and Iceberg. The new system delivers changes in 15 minutes to an hour, processes only changed records (saving significant compute since daily change rates are under 5% for most tables), and natively supports row-level deletes for compliance. The post walks through the architecture clearly and honestly covers the small-files problem and how they solved it with bucket joins for large-table upserts.
💡 Why is this relevant for DEs?
This is a textbook CDC + Iceberg architecture explained plainly. If you’re building or evaluating a real-time ingestion layer, Pinterest’s dual-table design (CDC table as append-only ledger, base table as the upserted mirror) is a pattern worth understanding before you design your own.
The small-files and bucket-join optimisations are the practical gold. Most blog posts stop at the architecture diagram. This one goes into how bucketing by primary key hash, WRITE DISTRIBUTED BY PARTITION, and a bucketed intermediate table for upserts cut compute costs by 40%+, details you can apply directly.
The compliance angle is increasingly important. Row-level deletes for GDPR and similar requirements are a real engineering constraint, not an afterthought. Seeing how Pinterest handled it in Iceberg with Merge-on-Read is directly useful for teams facing the same challenge.
Data Observability Fundamentals for Data Engineers
📖 Topic: Data Quality & Observability
🧠 Level: Beginner
Summary: A practical, tool-agnostic guide to detecting silent pipeline failures. It introduces six concrete detection patterns (Flow Interruption, Skew, Lag, SLA Misses, Dataset Tracker, Fine-Grained Tracker) and draws a sharp distinction between observability, a flashlight that catches surprises and data contracts, a laser that prevents known failures. One of the clearest pieces on this topic I’ve read this year.
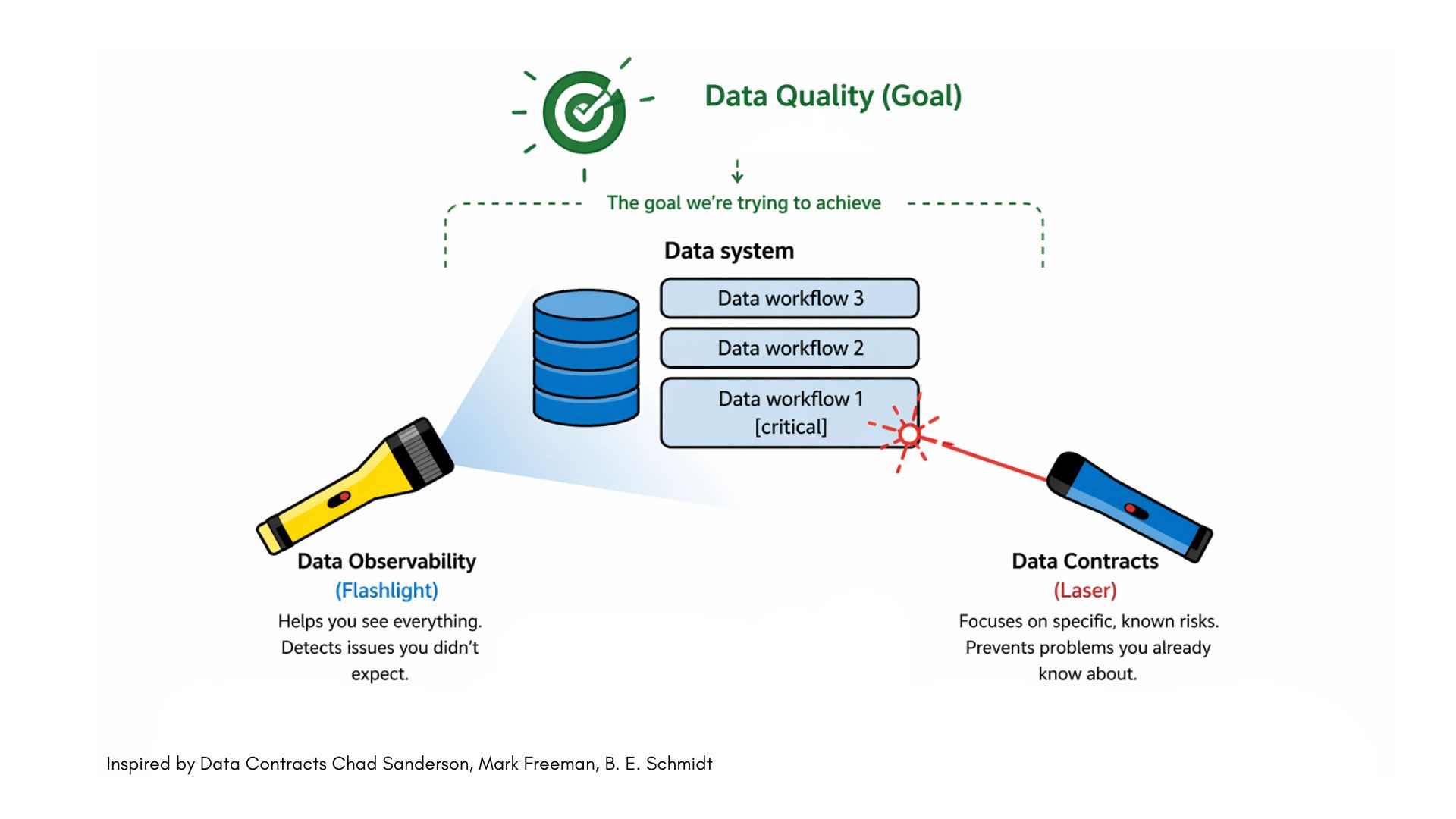
💡 Why is this relevant for DEs?
Observability first, contracts second that sequencing matters in practice and this post explains why clearly. Most teams get the order wrong and then wonder why their contracts don’t stick.
The six patterns are concrete enough to implement today, regardless of your stack. Most observability content stays at “monitor your freshness.” This goes further without requiring a specific vendor.
Silent failures are qualitatively more dangerous when AI is downstream. A schema drift that once broke a dashboard now corrupts model inputs at inference time. The stakes are different and this piece explains why.
Background Coding Agents: Supercharging Dataset Migrations (Honk, Part 4)
📖 Topic: Real-World Agentic Engineering at Scale
🧠 Level: Intermediate
Summary: Spotify used their internal coding agent Honk to migrate ~1,800 downstream data pipelines off two deprecated datasets — work estimated at 10 engineering weeks manually. They generated 240 automated PRs using Backstage lineage, code search, and their Fleet Management tooling. The post is honest about where it worked (standardised dbt and BigQuery Runner pipelines) and where it didn’t (their less-consistent Scio framework).
.png")
💡 Why is this relevant for DEs?
Context engineering - lineage, code search, test coverage is what made the agent useful, not prompt cleverness. The surrounding infrastructure determines how far an agent can actually go.
Standardisation is now a prerequisite for automation. Honk succeeded on consistent frameworks and struggled on inconsistent ones. If your pipelines are a patchwork of bespoke patterns, agents will hit the same walls human engineers do, just faster.
The migration use case is the most credible near-term application. Greenfield agentic pipelines are exciting in demos. Real ROI right now is in deprecations, schema migrations, and backfill rewrites; this post gives you a concrete template.
Semantic Layer vs. Text-to-SQL: 2026 Benchmark Update
📖 Topic: Data Modeling in the AI Era
🧠 Level: Intermediate
Summary: dbt Labs re-ran their 2023 benchmark with today’s LLMs (Claude Opus 4.6, GPT-5.x and more). The gap has narrowed, models are dramatically better at text-to-SQL. But for questions within a well-modeled Semantic Layer, accuracy hits near 100%, because MetricFlow generates SQL deterministically: the LLM picks the metric and dimension; the engine handles the query. The benchmark is open-source and reproducible on your own data.

💡 Why is this relevant for DEs?
The failure modes are what matter. Text-to-SQL fails unpredictably and silently. The Semantic Layer fails loudly (”I can’t answer that”). For production AI agents querying your data, the deterministic failure mode is far more manageable.
This is the empirical case for data modeling in the AI era. AI doesn’t make semantic consistency less important — it makes ambiguous metric definitions actively dangerous at inference scale. If your team is debating whether to invest in MetricFlow, this benchmark is the answer.
The 2026 State of Data Engineering Survey (Interactive)
📖 Topic: Agentic AI Adoption & The State of the Profession
🧠 Level: Intermediate
Summary: Joe Reis, the same person who reframed data modeling at DIS2026, surveyed 1,101 data engineers in early 2026 and published the results as a fully interactive explorer: filterable by role, org size, industry, and region, with raw CSV download and a SQL query interface on top of the dataset. The headline findings are striking: 82% of engineers use AI tools daily, but 64% of organisations are still experimenting or using AI for tactical tasks only. The biggest bottlenecks aren’t technical, legacy systems top the list, but lack of leadership direction and poor requirements are close behind.

💡 Why is this relevant for DEs?
The gap between individual AI usage and organisational adoption is the most actionable number here. Most engineers are already using AI heavily; most organisations haven’t built the workflows, governance, or data foundations to deploy agents at scale. That gap is where data engineers can have the most impact right now: building the infrastructure that closes it.
The modeling pain point is validated at scale. 59% cite “pressure to move fast” as their top pain point and only 11% say modeling is going well. If you’ve felt this tension in your own team, you’re not alone and the survey gives you real data to bring into conversations about prioritisation and technical debt.
The interactive format makes this genuinely useful beyond the headline numbers. You can cross-tab by org size, region, or industry to find findings specific to your context which is far more valuable than a static report summary. It’s worth spending 20 minutes in the explorer rather than just reading the takeaways.
How Meta Used AI to Map Tribal Knowledge in Large-Scale Data Pipelines
📖 Topic: AI-Assisted Data Platform Engineering
🧠 Level: Advanced
Summary: Meta’s engineering team built a pre-compute engine, a swarm of 50+ specialised AI agents, to systematically extract and encode the undocumented tribal knowledge buried across a large-scale data pipeline spanning four repositories, three languages, and 4,100+ files. The result: 59 concise context files covering 100% of code modules (up from 5%), 50+ non-obvious patterns documented for the first time, and ~40% fewer AI agent tool calls per task. The key design principle is “compass, not encyclopedia”: each context file is 25–35 lines, actionable, and auto-refreshed on a schedule so stale context can’t accumulate.
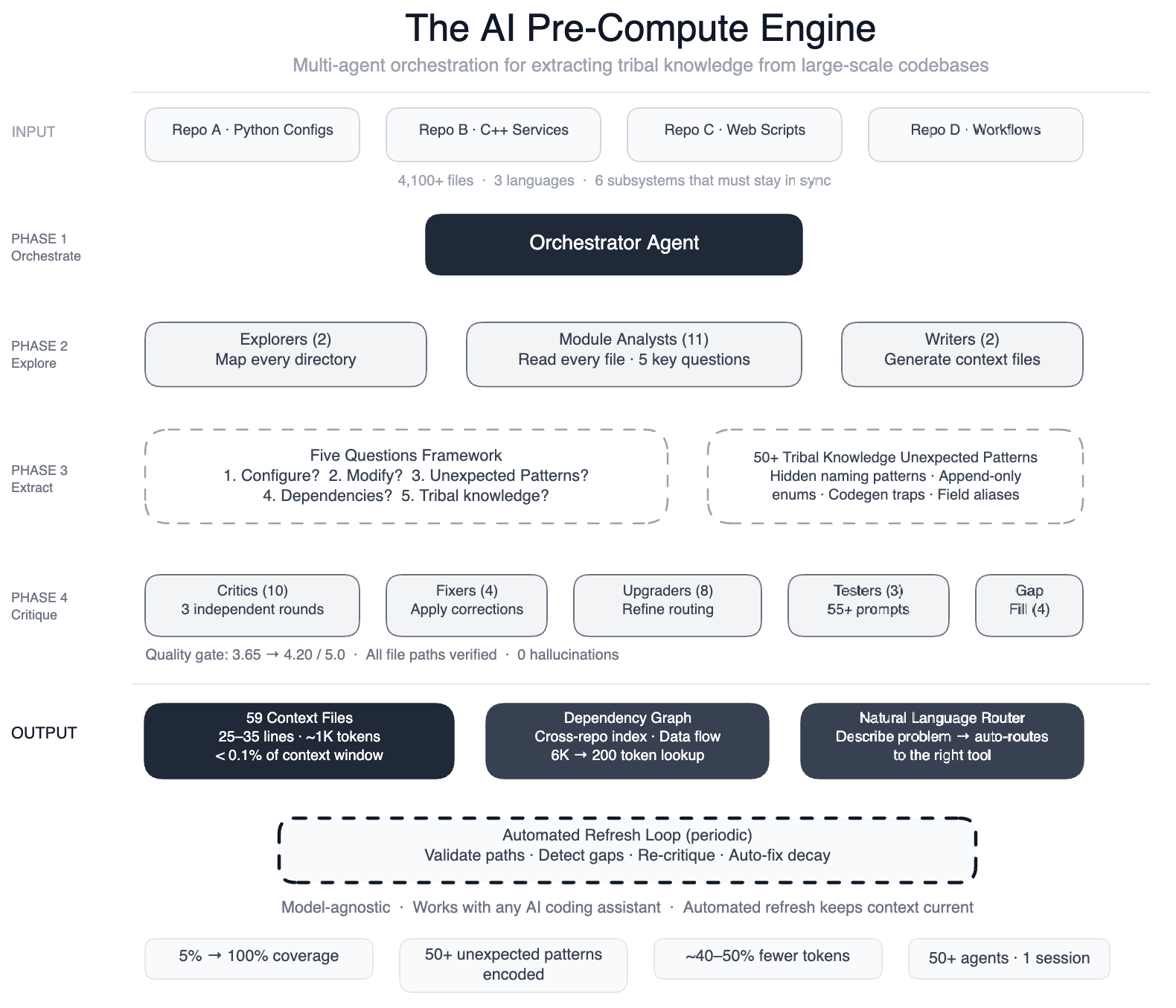
💡 Why is this relevant for DEs?
Tribal knowledge is the real blocker for AI agents in data platforms. Generic coding agents fail on proprietary pipelines not because the models are weak, but because they have no map, they don’t know your naming conventions, cross-module dependencies, or the silent rules that break builds. This post is the clearest description I’ve seen of how to fix that.
The “five questions” framework is directly applicable to your codebase today. For each module: what does it do, how do you modify it, what breaks silently, what depends on it, and what’s only in someone’s head? Running that exercise even manually will surface patterns you didn’t know were undocumented.
Self-refreshing context is the part most teams miss. Meta automated periodic validation and re-generation of context files, because stale context causes more harm than no context. If you’re building any agent-assisted tooling on your data platform, freshness of the knowledge layer is as important as its accuracy.
💎 Open Source Gem
Apache Fluss (Incubating) — Streaming Storage for Real-Time Lakehouses
Apache Fluss is a streaming storage system, now in Apache incubation, that sits as a hot real-time layer in front of your lakehouse. The core idea: instead of choosing between a Kafka-style streaming system and a file-based lakehouse, Fluss gives you both under one table abstraction. It writes sub-second streaming data in Apache Arrow columnar format, then a built-in tiering service continuously compacts that data into standard lakehouse formats: Iceberg, Paimon, or Lance, making it queryable by Spark, StarRocks, Trino, and Flink without any extra pipeline plumbing.
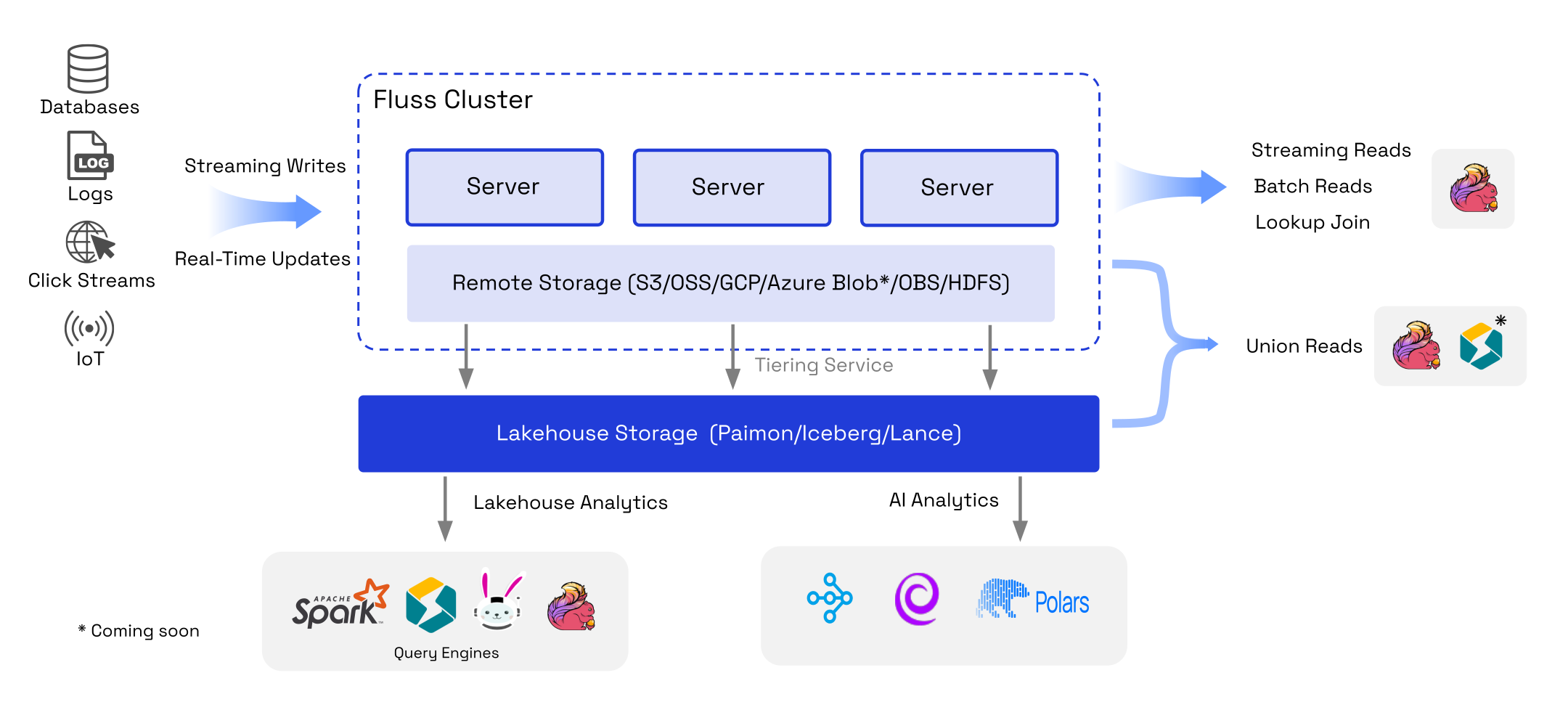
📰 What’s new / why now
The 0.8 release added full Streaming Lakehouse support for Apache Iceberg (continuously tiered, with exactly-once semantics and built-in compaction) and Lance (the vector-native format for AI/ML workloads). The headline feature is Delta Joins with Flink by externalising join state into Fluss tables, Flink performs joins incrementally on data deltas, cutting CPU/memory by up to 80% and checkpoint durations from 90 seconds to 1 second in early production deployments. It’s now fully compatible with Flink 2.1.
💡 Why is this useful for DEs?
It solves the oldest problem in streaming lakehouses. File-based formats like Iceberg have a practical lower latency bound of ~1 minute due to file commit overhead. Fluss breaks that wall by acting as the hot tier, giving you sub-second freshness without abandoning Iceberg for historical analytics.
One table, two access patterns. Flink can union-read both the real-time Fluss data and the compacted Iceberg history in a single query, no separate pipelines, no data duplication, no metadata inconsistency between streaming and batch layers.
Delta Joins are a genuine step forward for stateful streaming. If you’ve ever dealt with Flink state explosion on large join operations, externalising that state into Fluss is a meaningful architectural improvement, not just a configuration tweak.
👉 GitHub: https://github.com/apache/fluss
💡 DE Tip of the Month
Managing Query Costs in Cloud Data Warehouses Through Tagging and Attribution
Cloud data warehouses bill by compute consumed, which means a single expensive query from an untracked workload can inflate costs significantly before anyone notices. In many organisations, warehouse spend grows with usage but the breakdown, which pipelines, teams, or jobs are responsible, etc remains unclear until the bill arrives. Building cost attribution into your warehouse setup from the start makes spend visible, accountable, and actionable.
📒 Rules of thumb
Apply query tags or labels at the session or job level. Most major platforms (Snowflake, BigQuery, Databricks) support attaching metadata to queries like a pipeline name, team identifier, or environment tag. Doing this consistently means your query history becomes a cost ledger you can slice by workload, not just a raw list of executions.
Set warehouse or compute cluster size limits relative to the workload type. Transformation jobs and ad-hoc exploratory queries have very different compute requirements. Routing them to appropriately sized resources rather than a single general-purpose warehouse prevents exploratory queries from consuming resources provisioned for production pipelines.
Schedule cost reviews as part of your regular pipeline health checks. A query that was efficient at last year’s data volumes may be expensive today. Reviewing the top consumers by compute spend on a regular cadence surfaces regressions early, before they accumulate.
Use query result caching deliberately. Repeated identical queries common in BI dashboard refreshes can often be served from cache at zero compute cost. Verify that caching is enabled for appropriate workloads and that transformations upstream are not inadvertently invalidating it on every run.
📊 Community Poll
Until next time, cheers!
ℹ️ About Data Engineer Things
Data Engineer Things (DET) is a global community built by data engineers for data engineers. Subscribe to the newsletter and follow us on LinkedIn to gain access to exclusive learning resources and networking opportunities, including articles, webinars, meetups, conferences, mentorship, and much more.
Reading about the agentic AI journey and the future of Data Engineering in this era is so interesting.
> 82% of engineers use AI tools daily, but 64% of organisations are still experimenting or using AI for tactical tasks only
This, and Meta's project to systematically extract and encode undocumented tribal knowledge, really shows that two topics will dominate conversations in the near future: driving adoption and moving fast enough for large companies that may struggle to keep pace, combined with context engineering.
Smazing selection of topic Chozhan, Sri, & Ananda 💛!
Thank you so much for the mention, it’s an honour to be part of this list and the Data Engineer Things.