
Data Engineer Things Newsletter - Data Pulse Edition (Jan 2026)
DET editors' New Year resolutions, templatizing Spark declarative pipelines, Meta's video invisible watermarking, Lyft's feature store architecture





First of all, Happy New Year, everyone!
Hope you all had a happy and restorative holiday season. My own break was a beautiful blur of firsts: spending the first Christmas and New Year with my new daughter. There is something profoundly grounding about watching a child experience the magic of a Christmas market for the first time. Between the smell of roasted nuts and the twinkling lights, I found myself doing a different kind of “data collection”capturing every giggle and wide-eyed stare.
That calm period gave me some much-needed space to reflect on 2025. In the data world, 2025 was the year we stopped talking about AI alone and started weaving it into our actual pipelines. We moved from Copilots that write SQL to AI-assisted metadata management. Personally, it taught me that while the tools change faster than a toddler’s mood, the fundamentals: reliability, cost-efficiency, and trust remain our North Star.
Let’s make 2026 the year we build less “tech debt” and more “data wealth.”
With that, we start our first newsletter of the year with a bonus section. A few of our DET editors share their New Year Resolutions with you, our amazing community. Hope you enjoy this edition and perhaps draw some inspiration for yours, if you’re in the process of creating your own.
- Chozhan
📚 Data Pulse
Templatizing Spark Declarative Pipelines with DLT-META
📖 Topic: Data Pipelines
🧠 Level: Beginner
Summary: Databricks introduces DLT-META, an open-source framework designed to solve pipeline sprawl. It allows engineers to use a metadata-driven approach to generate Delta Live Table (DLT) pipelines. Instead of writing unique code for every table, you define the pipeline logic in a JSON/YAML template, and the framework dynamically generates the Spark jobs.
💡 Why is this relevant for DEs?
Operational Scalability: It enables us to move from “coding” individual pipelines to “architecting” frameworks, allowing a single engineer to manage thousands of tables.
Reduced Tech Debt: By templatizing the logic, you ensure consistent data quality checks (expectations) and governance across all data assets.
Faster Onboarding: New data sources can be integrated by simply updating a metadata file rather than deploying new code modules.
DRY (Don’t Repeat Yourself): It enforces a “standard library” of transformations, making maintenance and debugging significantly simpler across the lakehouse.
Meta: Video Invisible Watermarking at Scale
📖 Topic: Data Engineering
🧠 Level: Intermediate
Summary: Meta uses Video Invisible Watermarking, a system designed to embed traceable metadata into video content without affecting visual quality. This enables Meta in detecting AI-generated videos, verifying who posted a video first, and identifying the source and tools used to create a video. This is a massive-scale data engineering challenge given the amount of videos being circulated across Meta platforms every minute. It requires processing billions of video uploads in real-time, ensuring the watermark survives compression, cropping, and screen recording. In this post, Meta shares how they overcame the challenges of scaling invisible watermarking, including how they built a CPU-based solution that offers comparable performance to GPUs, but with better operational efficiency.
💡 Why is this relevant for DEs?
Complex Data Modeling: It showcases how to handle unstructured data as a first-class citizen in a pipeline.
High-Throughput Processing: DEs can learn about the infrastructure required to run computationally expensive ML models (for watermarking) on every single write operation.
Data Provenance and Trust: As GenAI content floods the web, building “Trust Infrastructure” like watermarking will become a core responsibility for data platforms.
Multimodal Engineering: It bridges the gap between traditional signal processing and modern distributed data pipelines at an exabyte scale.
Lyft’s Feature Store: Architecture, Optimization, and Evolution
📖 Topic: Data Architecture
🧠 Level: Advanced
Lyft's revamped Feature Store is a mission-critical "platform of platforms" designed to centralize and scale machine learning feature management across the organization's entire rideshare stack. The implementation utilizes a "Features-as-Code" approach where engineers define features via Spark SQL for business logic and JSON for metadata. This configuration is automatically converted into production-ready Airflow DAGs that compute and publish data to both a Hive-based offline store for training and a high-performance online serving layer. For low-latency retrieval, the system employs a hybrid architecture featuring DynamoDB backed by a ValKey write-through cache, alongside OpenSearch specifically for vector embedding support. This robust setup now handles over a trillion annual operations, serving as the foundational infrastructure for everything from real-time pricing to fraud detection.
💡 Why is this relevant for DEs?
Democratizing feature engineering: By allowing anyone with SQL and JSON knowledge to deploy production-grade pipelines.
Separating storage and computation: To ensure high-throughput batch writes never interfere with sub-millisecond read performance.
Solving the small file problem: Through automated background compaction and clustering within the streaming lakehouse layer.
Enforcing organization-wide Data Contracts: Guaranteeing feature freshness, ownership, and schema stability for downstream consumers.
Reducing operational overhead: By migrating complex orchestration from in-house tools to managed services like Astronomer (Airflow).
Future-proofing infrastructure for AI: With native vector indexing in OpenSearch to support emerging LLM and agentic workflows.
Standardizing multimodal data management: Unifying raw metadata, binary blobs, and embeddings into a single searchable ecosystem.
💡Blog: Building AI Agents for Data Engineering Ops
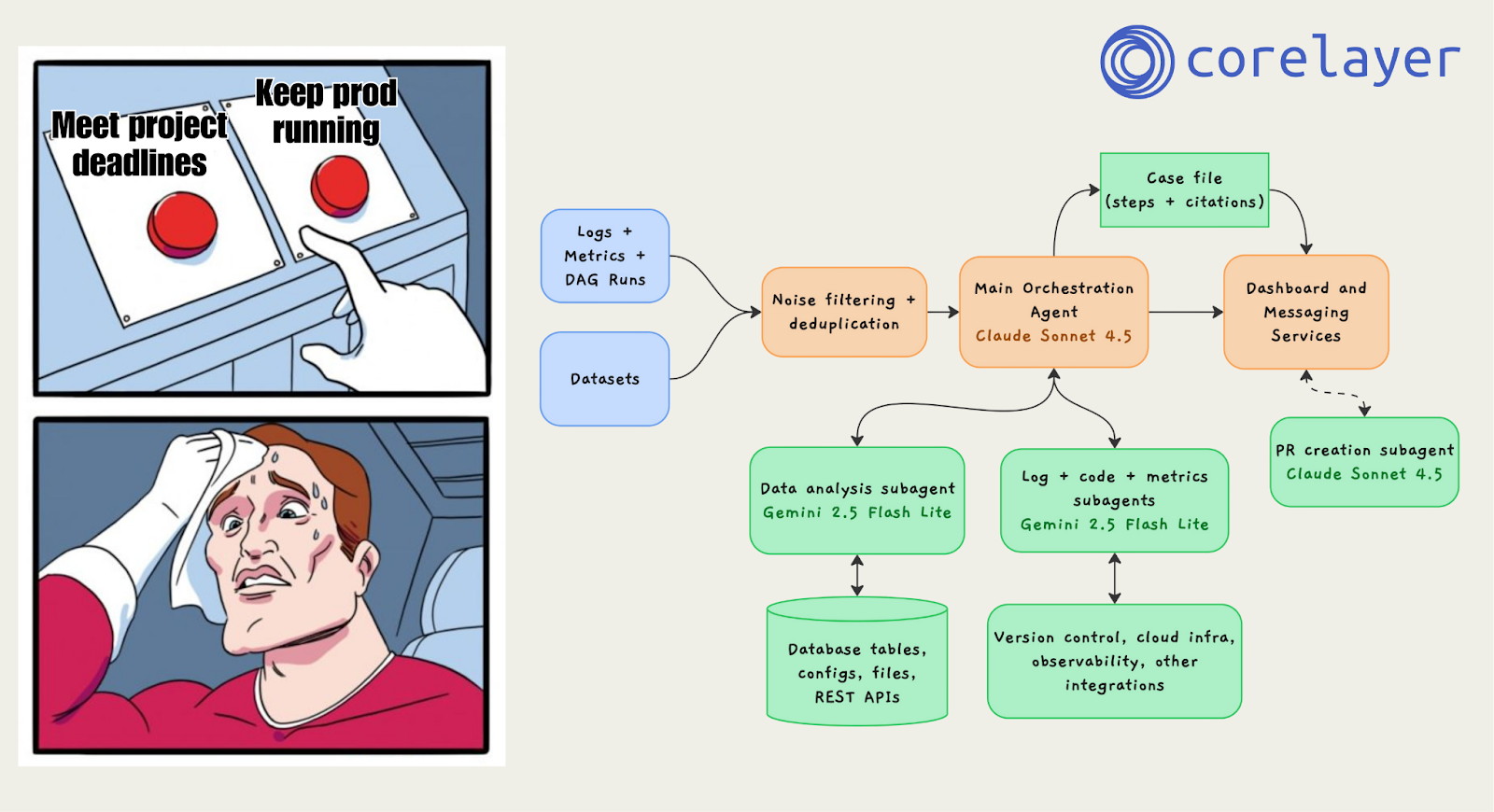
Debugging production data pipelines is a critical part of a data engineer’s job but it can be particularly difficult. The team at Corelayer explored how AI agents can assist with investigations: detecting anomalies, correlating logs and DAG runs, forming hypotheses, and producing evidence-backed root cause analyses with humans firmly in the loop. In this article, you will learn the failure modes, operational complexity, and the design principles (evals, guardrails, transparency) that matter when applying AI to real-world data engineering workflows.
👉🏼 Read the full article HERE.
(This message is sponsored by Corelayer.)
✨ New Year Resolutions from DET Editors
Volker
In our first Community Spotlight newsletter, the vote showed that the biggest blockers to write or speak about work and experiences are “stuck in drafts forever” and “too tired after coding all day.” I feel both. I tend to overthink everything I share, so ideas die in perfectionism. But data engineering moves fast, and the value of insights fades quickly. This year, I want to be braver: share earlier, share imperfectly, and don’t be afraid of having opinions.
Swetha
In 2026, I want to develop consistent technical writing in data engineering, using it to support others in the field and also make it as a learning tool. Alongside this, I want to also expand the mentoring guidance to provide aspiring data engineers, give them industry trends, interview expectations and help them achieve their goals, I have always loved contributing to the community and I look forward to taking the deliberate effort to do that this year.
Eddy
In 2026, my resolution is to create more conversations about data engineering. A lot of my growth as a data/software engineer came through meetups and having conversations with dev/product/sales/marketing folks across the tech spectrum. I’ve been fortunate to grow in a place with a vibrant data community, and that environment played a huge role in my professional and technical development. In the future, I hope to carry that same mindset forward: investing in conversations, building community, and learning in public.
Ananda
I plan to contribute to open source, as it gives me significant leverage to create impact across the data engineering community. I intend to increase my knowledge in large-scale data engineering and infrastructure optimization. A more ambitious idea is to learn a new programming language, probably Rust, to expand my skill set. I’ll share what I learnt with the community through mentoring, blogging, and speaking engagements, taking small, consistent steps that compound into decent progress.
Chozhan
Starting late 2025, we’ve been inching toward Autonomous Data Engineering, where pipelines don’t just alert us when they break, but suggest the fix or even auto heal. With that as an opportunity, I approach 2026 with the mindset of reclaiming the mental space for creative architecture & strategy that drives more business value by (re)designing every system to automate the mundane & repetitive. Also, I learned a lot in the past years from being part of communities and this year, I’d like to give back more by sharing my experiences, especially failures & lessons learned using different mediums.
So, dear community, we are curious to hear what your 2026 resolutions are. Let us know via the poll at the end 👇 or in the comments or the community chat 💬.
💎 Open Source Gems
LanceDB: The Multimodal Vector Database for the AI Era
LanceDB is an open-source, serverless-native vector database designed to simplify the management and retrieval of unstructured data for AI applications. Built on the high-performance Lance columnar data format, it offers up to 100x faster random access performance compared to traditional formats like Parquet. It is uniquely useful because it allows engineers to store raw data (images, videos), metadata, and vector embeddings together in a single, unified table. This "SQLite-like" approach means it can run embedded directly in your application or scale to massive cloud-native lakehouses without the overhead of managing a complex database cluster.

💡 Why is this relevant for DEs?
Unifies raw media and embeddings in a single table, eliminating complex sync logic between disparate data stores.
Eliminates Parquet’s random access bottleneck, delivering the sub-millisecond retrieval required for real-time RAG.
Scales from local to petabyte-scale cloud storage using an embedded, zero-infrastructure serverless architecture.
GitHub: https://github.com/lancedb/lancedb
💡 DE Tip of the Month
Build Context-Aware Metadata & Smart Lineage
Most lineage systems only show which tables depend on which, but context-aware metadata explains why changes happened and what triggered them. By capturing deployment info, config changes, and upstream data shifts, teams can perform faster root-cause analysis and smarter testing. This turns metadata into an operational control plane rather than passive documentation.
💡 Key ideas & how to apply:
Capture deployment metadata alongside data changes
Example: tagging runs in Airflow / Dagster with context.run_tags = { "change_type": "schema_update", "jira_ticket": "DATA-2411", "release": "v2026.01", "affected_columns": "order_status, delivery_eta" }Store these tags in your metadata system (OpenLineage, DataHub, Marquez).
Track schema evolution events and backfills explicitly (change_type = backfill)
Use this metadata to auto-trigger downstream tests & validations and feed lineage to impact analysis before major releases. When something breaks, you already know, what changed, who changed it, what downstream systems are affected, so the incidents resolve faster and safer.
Let us know what you like the most in the newsletter. See you next time!
Until next time, cheers!
Chozhan, Shubham & Sugandhi
ℹ️ About Data Engineer Things
Data Engineer Things (DET) is a global community built by data engineers for data engineers. Subscribe to the newsletter and follow us on LinkedIn to gain access to exclusive learning resources and networking opportunities, including articles, webinars, meetups, conferences, mentorship, and much more.