
Data Engineer Things Newsletter - Community Spotlight Edition (Mar 2026)
Why nobody believes "100x faster" benchmarks, and why the dedicated graph database might be dead.




Hi everyone,
This series is designed for one outcome - clear lessons on how experienced builders approach data engineering problems, not just a founder story or a project overview, so that our DET community can have reusable mental model on how to think about scale, operability under real constraints.
To kick things off, we sat down with Weimo Liu, co-founder of PuppyGraph, whose career spans database research, TigerGraph, and Google’s F1 team. His perspective is a perfect stress test for the themes we care about: why graph ideas have been academically compelling for decades, why production adoption is still hard, and how “scale” in industry changes what success even means. In this interview, Weimo walks through the shift from chasing benchmark wins to optimizing for cost and operability—and shares a provocative approach to graphs: running graph queries directly on modern table formats like Apache Iceberg, instead of asking enterprises to migrate and reload everything.
Let’s dive in and walk through Weimo’s journey.
- Swetha Sekhar
🎟️ Conference: Data Engineering Open Forum 2026

We are hosting the 3rd Data Engineering Open Forum (DEOF) on April 16 in San Francisco! Here is what you will experience expect at the event:
Sessions by speakers who are solving cutting edge problems in data engineering, for examples, Apache project creators and PMCs like Julien Le Dem, Boyang Jerry Peng, and Jack Ye.
Intentionally-designed activities that you can sign up to engage in small-group networking (because we know it’s hard to make conversations at conference).
Opportunities to connect with data engineering teams at top tech companies (like Netflix, Airbnb, and more) at their booths.
Our ultimate goal is that when you look back some day, you could confidently say “I’m so glad I went to DEOF”, because the people you met there or ideas you walked away with made a difference in your career.
👉 See the agenda HERE. RSVP before Early Bird price ends on March 11.
Spotlight: Weimo Liu
“I realized users weren’t really looking for a graph database, they were looking for the graph itself.”
For those in the DET community who may not know you yet, could you briefly introduce yourself?
Hi everyone — I’m Weimo. It sounds like the “self-driving” car, Waymo. I’m the co-founder of PuppyGraph. Before starting PuppyGraph, I worked at TigerGraph and Google’s F1 team. TigerGraph is a graph database startup, and F1 is Google’s internal unified SQL query engine, serving billions of queries per day. Thanks so much for having me, it’s a real pleasure to be here.
You’ve been working in the database world since your PhD years. Tell us about your career journey — what initially drew you to databases, and what kept you in the space for so many years?
Back in college, I did very well in my data structures class, and my professor invited me to join his lab. That led me into database research, where I published papers on spatial databases.
When I applied for PhD programs, I actually looked up professors who had published heavily at SIGMOD and VLDB in recent years, and found my advisor Dr. Zhang.
After my PhD, I joined TigerGraph. The founding CTO was a close friend of Dr. Zhang, and I worked there for almost three years. Later, I joined Google — partly because it felt like a safe choice — and worked on the F1 team.
What keeps me in databases is that the field is very concrete. The problems are understandable, progress is measurable, and when something improves, you can usually prove it.
You once said that “half the database papers back then were about graphs.” What made graph workloads so captivating for researchers?
First, graphs are hard. The data is highly connected, and it’s very difficult to shard and distribute efficiently, which constantly creates room for new algorithms and system designs.
Second, motivation is very natural. Researchers don’t need to invent artificial use cases just to justify the work — real graph problems already exist everywhere, such as anti-fraud, network observability, social network analytics, and cybersecurity.
Third, graph theory in mathematics is extremely rich. Computer scientists can borrow powerful ideas from math and turn them into systems that are both interesting and practical.
After your PhD, you took your first industry role at TigerGraph. What surprised you most about the difference between academic database research and real-world database engineering?
In academia, performance is everything. You aim for benchmarks that are 10× faster than the state of the art.
In industry, speed alone doesn’t mean much. Cost, scalability, operability, these often matter far more. You can’t just spend unlimited resources to get a better benchmark number.
Also, no one really cares about “10× faster,” or even “100× faster.” If you walk around AWS re:Invent, every product claims to be 100× better than the state of the art, without even defining what that state of the art is. There’s no peer review, and nobody truly believes those numbers.
Later at Google, you worked on database systems at a much larger scale. What kinds of problems were you solving there, and how did that experience change how you thought about data systems?
F1 is a federated query engine that can query almost every data source and format inside Google. It serves billions of queries per day and handles most of Google’s OLAP workloads — from the fastest, most expensive systems to the slowest, cheapest ones.
In the early days, Google had many different OLAP systems across different organizations. Over time, more and more teams connected their data sources to F1. Eventually, most of them were either deprecated or absorbed into the F1 ecosystem.
That experience made me realize how important unified federation really is.
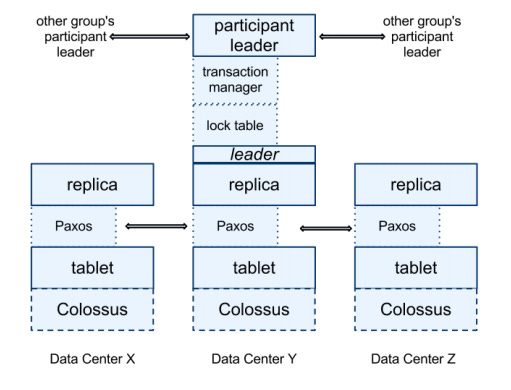
💡 Editorial Note: F1
F1 is Google’s globally distributed SQL database built on top of Spanner, giving full relational features (SQL, ACID, secondary indexes) at planetary scale. Spanner handles sharding, replication via Paxos, and external consistency using TrueTime (a globally synchronized clock), while F1 provides a stateless SQL layer that parses, optimizes, and executes distributed query plans. Data is organized with hierarchical, interleaved tables to co-locate related rows in the same key ranges, reducing cross-shard transactions. Writes use Spanner’s two-phase commit across replicas, and reads use consistent snapshots. In short, Spanner provides globally consistent distributed storage, and F1 turns it into a fully featured distributed SQL database.
👉 Read the full F1 paper HERE.
👉 Read the full Spanner paper HERE.
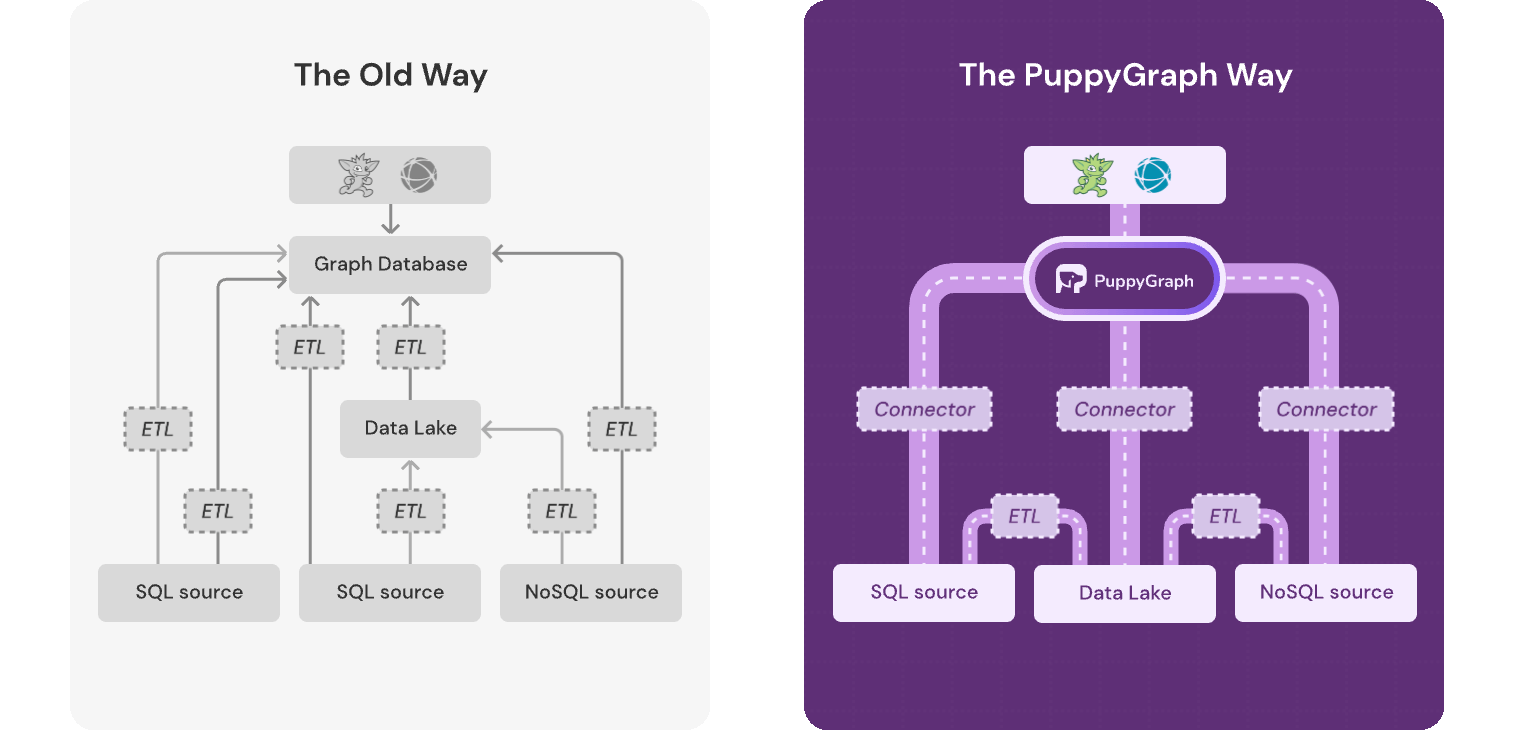
What prompted you to write a new graph query framework? What problem did you feel wasn’t being solved, or wasn’t being solved in the right way?
I had been thinking about this for a long time. At TigerGraph, many potential users showed strong interest in graph technology, but most of them couldn’t actually adopt it in production. For example, a large bank spent 18 months loading all of its data into the system — something that would be unrealistic for most enterprises. That told me something fundamental was wrong.
After joining Google’s F1 team, I realized these users weren’t really looking for a graph database, they were looking for the graph itself.
I didn’t start the project immediately because, unlike Google, the external data world wasn’t standardized. That changed when I read an a16z blog post announcing that the Apache Iceberg team had left Netflix to found Tabular. I realized the timing was finally right.
My co-founders and I actually reached out to the Apache Iceberg creators with a very simple demo: running graph queries directly on Iceberg, faster than most graph databases on the market. That surprised them too, they hadn’t optimized Iceberg for graph workloads at all. They supported us a lot, not just on engineering, but also on go-to-market.
During the development of the framework, what were some of the hardest technical problems you had to solve?
Graph systems are notoriously difficult to scale, which is one of the main reasons they have not been widely adopted by enterprises with very large datasets.
We define the operators in a graph query plan as NodeOperators and EdgeOperators, where the input and output of each operator is a collection of nodes or edges. PuppyGraph assumes that all graph queries, patterns, and algorithms can be expressed as combinations of these operators.
PuppyGraph implements a rule-based optimizer for logical query execution plans, and a hybrid rule-and-cost-based optimizer for physical execution plans. Because all inputs and outputs are collections, any individual operator can be massively parallel processed (MPP) and vectorized for evaluation.
How did you find your co-founders and early team members, and what qualities did you look for when building the team?
They’re all old friends. Our CTO was my college roommate, and our chief architect lived next door. They’re well-known competitive programming contestants, and honestly, much better programmers than I am.
Trust mattered the most. In the early days, you need to move fast and collaborate extremely smoothly. We were lucky to have already built that trust years ago, it really feels like a reunion of old teammates.
Has the graph problem space changed in response to the rise of AI? Where do you think the field is actually heading?
Yes, very much so. Initially, we didn’t think of this problem space as being closely related to AI. But more and more AI companies and AI teams started reaching out.
AI generates more data, and at the same time, it activates a lot of previously “cold” data. A human data analyst might be able to keep track of hundreds of tables, but AI systems can reason over thousands or even more simultaneously. Our view is that when you already have tables, you already have knowledge. You don’t need to build a separate knowledge graph — you can simply treat your existing data as a graph. That structure naturally provides context to LLMs.
Before we let you go… who should we interview next, and why?
Haha — I’d suggest Zhou Sun, the co-founder of Mooncake Labs. He’s sharp, opinionated, and deeply knowledgeable about databases. I think it would be a really engaging conversation.
Key Takeaways
The central reframing: many teams don’t need “a graph database”; they need graph type queries over the data they already have, and open table formats like Apache Iceberg make that approach more feasible.
AI shifts the bottleneck from “finding data” to “connecting data with meaningful relationships” When AI can reason across thousands of tables, the problem becomes building reliable structure/context across them.
Weimo’s differentiator is translation: turning research-grade system design into something enterprises can run—where operability and time-to-value matter as much as performance.
Community poll
💬 How to stay connected
ℹ️ About Data Engineer Things
Data Engineer Things (DET) is a global community built by data engineers for data engineers. Subscribe to the newsletter and follow us on LinkedIn to gain access to exclusive learning resources and networking opportunities, including articles, webinars, meetups, conferences, mentorship, and much more.