
Data Engineer Things Newsletter - Community Spotlight Edition (June 2026)
The craft is no longer in the code. It’s in how you define context, questions and evaluations




Hi everyone,
In our next iteration of the community spotlight, we are chatting with Shridhar Iyer, Director of Data Engineering at Meta.
Shri has spent over a decade navigating and shaping the major shifts in data engineering. Today, he is at the forefront of transitioning traditional data systems into AI-native architectures. In this spotlight, we dive into his journey from software engineering to unifying Meta’s massive data foundations, explore how AI is rewriting the development workflow for data engineers and how to position yourself for success.
Let’s dive in and walk through Shri’s journey.
- Eddy Zulkifly & Swetha Sekhar
Spotlight: Shridhar Iyer
“Building a shared identity around the work scales impact far beyond what any single team could achieve.”
For people who may not know your journey, how would you describe the path that brought you here?
I started my career in software engineering working on supply chain, logistics and enterprise systems. Early on, I learned that leverage wasn’t in building the systems, but rather understanding the business deeply enough to influence it. At a retail analytics startup, I got my first taste of what it meant to scale analytics across Fortune 500 companies and found myself drawn to systematizing and unifying the chaos of different datasets and process. The work entails schematizing workflows and building tools that made fragmented processes legible. That impulse followed me to Meta.
At Meta, I started by building the analytical foundations that helped measure how people used Facebook. I curated datasets that became central to how the company understood itself and developed frameworks that standardized how growth and engagement were measured across the entire product. Later on, I moved into the Search team and worked on real-time streaming, sessionization and bridging business logic between batch and real time. Each experience exposed me to a new layer of fragmentation and each time, my instinct was to unify it.
That drive toward unification made me realize that making data accessible to more people across a complex platform required more than pipelines and dashboards. It required data to be understandable at all points of development and doing so securely.
What has changed most dramatically in data engineering during your time at Meta?
Having lived through every major shift in data engineering over the past decade, AI has been a dramatic shift in terms of data engineering work. Distributed compute, new storage formats, streaming and CI/CD changed how the work was done, but left the fundamental contract intact. A data engineer expressed logic in SQL or Python, wrapped it in pipelines, and governed it through pull requests. The interface between human and machine stayed the same.
AI breaks that contract entirely.
The nature of the work changes, from physical to conceptual, from writing logic to specifying intent and from governing code to governing knowledge. The craft is no longer in the code. It’s in the quality of the question, the rigour of the eval and the integrity of the context you feed it. Writing good evals is a hard problem. Designing agentic workflows with the right guardrails is a hard problem. Knowing what knowledge actually matters to an AI agent, and governing it well, is a hard problem. Even measuring the output from AI reliably has been harder than expected. The work is no longer about using AI as a tool but rather becoming AI-native. It’s about rebuilding how you think, design, and measure from the ground up.
Existing codebases have to be made AI-ready with appropriate tradeoffs. The development lifecycle itself is up for reinvention as spec-driven development and agentic loops are replacing what were once manual workflows. What constitutes good work is shifting from optimizing the science to encoding the art. Turning repeatable expertise into skills, expressing domain knowledge as governed context and designing for a machine that reasons differently than we do.
You’ve written about unifying semantic context across data systems. What does that look like in practice?
A while back I wrote about the intelligence pyramid: Data → Information → Knowledge → Wisdom, and more recently revisited it through an AI lens. It’s a practical blueprint for how semantic context for data can be built, evolved, and directed towards AI Agents. Each layer builds on top of the other.
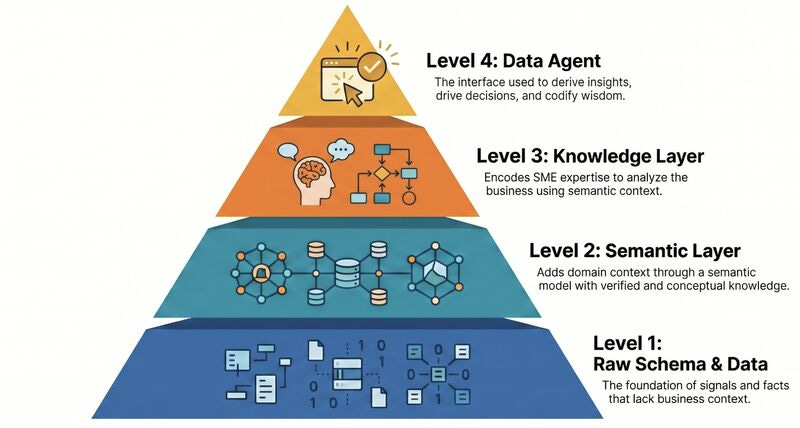
Historically, the ROI for semantically modeling data for analytics alone was hard to justify at scale. AI changes this by making human workflows drastically cheaper but it requires structured knowledge to become effective.
The raw schema & data layer is where most warehouses live today. Physical tables with primitive column types that don’t convey meaning or purpose. Making this layer semantically understood required introducing richer schema annotations, a type system that encodes meaning at the column and table level, and a unified taxonomy governed at source in online systems that flows into the offline warehouse. This also required unifying the metadata and asset catalog, covering tables, columns, sub-columns, dashboards, and all asset classes, along with column-level lineage and the SQL language itself through a compiler. That effort was primarily driven by privacy and security, but it built the foundational layer of semantic understanding that everything above depends on.
The semantic layer encodes what the data means in a business context. Assets include a domain glossary, metric and dimension definitions, verified queries, and table selection guidance. This is the tribal and institutional knowledge that makes data of a domain genuinely useful but rarely governed or structured well enough to scale.
The knowledge layer encodes the analytical skills and methodologies that experts use to produce insights. The business process of growth accounting, retention, root cause analysis, opportunity sizing. Encoding them as governed primitives is what democratizes the craft. It allows non-SMEs the same analytical capability that previously required years of domain experience.
At the top, the data agent consumes all three layers to reason over enterprise data in real time, composing governed domain knowledge into trustworthy answers.
What we are formalizing is the long-term memory of the enterprise and the skills of its subject matter experts into a governed, composable system. All of this required the same design instinct at every layer: unify the representation, govern it at source, catalog it canonically, change-manage it at scale, and make it consumable, whether by a privacy enforcement system or an AI data agent.
How do you measure whether AI initiatives are truly successful in data engineering teams?
Measuring AI success in data engineering starts with recognizing that the work falls into two distinct but deeply interdependent buckets which are AI readiness and AI-native workflows.
AI readiness is about making your data systems legible to AI. Well documented schemas, semantic context, code and lineage that an agent can reason over. AI-native workflows are about reimagining the development and consumption lifecycle itself, both the inner loop of discovery, authoring, testing, review, and deployment, and the outer loop of scheduling, anomaly detection, quality enforcement, backfills, and privacy compliance, and the consumption side of visualization, reporting, analysis, and security enforcement.
The most common measure in practice has been adoption which can be measured by committed diffs, tool usage, active users. While adoption is a real signal, adoption alone masks the harder question, which is quality. Some productivity lift is nearly always present when using AI tools. The challenge is assessing if the output is trustworthy enough to act on. For example, instead of vaguely measuring "time saved," leaders must look at cycle-time reduction for specific, repeatable tickets, like tracking the average hours it takes to onboard a new data source or generate a new dbt model with an AI assistant versus without one.
That’s where evals become the more rigorous measure. Evaluating whether an AI agent produced the correct query or insight is genuinely difficult, especially for open-ended analytical tasks where there isn’t always a single correct answer. In data engineering, this means moving beyond simple code-syntax validation to behavioural evals. For instance, an inner-loop eval might test whether an AI agent can refactor a legacy SQL script into clean, optimized dbt code without altering the underlying data output. An outer-loop eval might test whether an AI agent can accurately root-cause a pipeline anomaly alert and point to the exact upstream schema change that caused it.
It also helps to think about measurement through these two distinct groups, namely builders and domain experts. Builders or engineers have taken to AI most naturally and construct the agentic workflows. Domain experts or the people who hold the institutional knowledge, are finding it harder to translate that expertise into AI leverage. The gap between these two groups is itself a measure of how much work remains.
The north star measure, autonomous agents planning, reasoning, and executing full analytical workflows with minimal human input, is still ahead of us. We are not yet there outside of the most obviously repeatable task patterns. What leadership can measure today are these metrics:
Readiness Coverage: The percentage of production data models that possess verified, LLM-legible semantic tags and up-to-date lineage maps.
Adoption Depth: The frequency and consistency of AI tool usage across both builders and domain experts.
Eval-driven Quality Scores: The pass rate of AI-generated assets against rigorous regression test suites.
Workflow Completion vs. Step Acceleration: The degree to which AI is autonomously finishing end-to-end workflows rather than just accelerating isolated steps within them.
Workflow completion, is perhaps the most honest indicator of where any team truly stands.
What is the biggest leadership shift from managing teams to operating at the Director level?
I should be honest about something upfront, I was never a traditional org manager in the strict sense. I have led teams both informally and formally as a tech lead manager, but my formal expectation has always been that of a tech lead, meaning I have always been held to an IC bar even at the director level. For the past few years I have been operating as a pure IC. So I think of this less as a shift from manager to director and more as a shift in how you operate and what you optimize for at a higher level of ambition.
The first shift is cognitive. As an IC, you are in the details. As a director, you are defining which problems are worth solving and setting the principles that guide multiple teams toward coherent solutions. The craft moves from execution to framing. Framing well requires the ability to see how the systems interact interact, where they conflict and articulating the problem concisely to a large group of people across different functions, roles, and levels. That is harder than it sounds.
The second shift is organizational, and for me it has always come back to the same instinct of unification. The biggest risk at this level is fragmentation where teams are building good things independently that don’t compose. Most of my largest initiatives have been cross-functional, spanning different orgs, roles, and levels, held together not by authority but by a shared conviction about what’s possible.
That conviction has to be earned. It starts with thinking like the exec in your reporting chain. What would a VP want to know about your product area? What does the future look like, not just for your product but for the function it serves? If you can’t answer that crisply, you are not ready to drive adoption of anything. You have to think objectively about what is best for the company, not just your team. When you frame your initiative around long-term company health rather than local goals, adoption stops being a sales pitch and starts being an obvious move.
Then there is clarity. I compensate for not being a natural presenter through writing, especially when it comes to articulating ambiguous problems. Going deep enough to produce a prototype, a proof of concept, or a clear vision is what makes the destination visible. When people can see the destination, they find their way toward it.
Pre-reads matter, but in front of a senior audience, most of the time is spent on discussion. Think through your questions deeply. What will decision makers push back on? What is the elephant in the room, and can you surface it explicitly? Influence at this level is less about presenting and more about orchestrating the right conversation. And if leadership is wrong, say so, but focus on alignment rather than proving someone wrong.
Orchestrating conversations this way builds a shared identity around the work scaling impact far beyond what any single team could achieve.
Where do you think AI genuinely helps data engineers today, and where does it create over-usage or overconfidence?
AI genuinely helps during the inner and outer development loops. In the inner loop, agentic workflows deliver the most value during coding and development, triggering autonomously on the right conditions and passing through existing guardrails like test cases, data quality checks, and human review gates. The outer loop follows the same logic, detecting what changed in the logic, handling backfills and failures, auto-healing where appropriate. Beyond these loops, everything depends on rigorous evals to validate and without them, you are only assuming effectiveness.
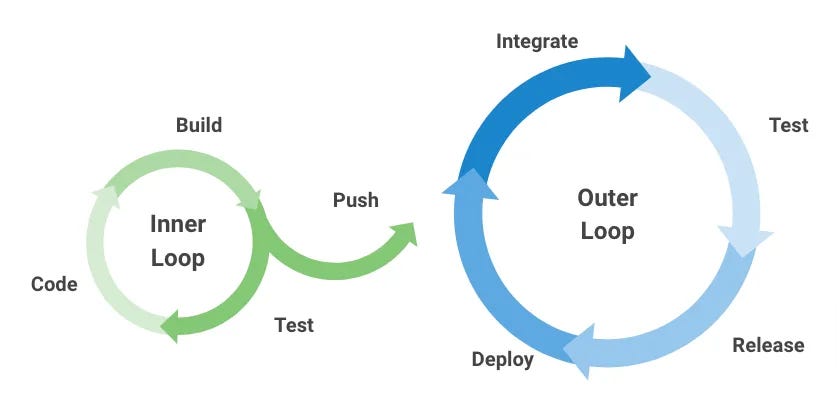
Overusage most commonly stems from not designing AI workflows purposefully. Almost every AI workflow is, at its core, an event-driven pipeline. When it is not designed that way, you end up reprocessing large volumes of information in unstructured formats, wasting tokens on work that could have been scoped and triggered more precisely. Another common example is not knowing which model is right for the job, reaching for a more capable and expensive model when a lighter one would suffice. Similarly, running evals on a recurring schedule to test changing context is a source of waste. The right design detects when a change happens and triggers the eval then, not continuously.
Overconfidence is the more consequential failure mode. Agents are built to find an answer, and they will, even when they should not. A silent infrastructure failure, a discovery service going down for something as straightforward as a daily active user query, will not stop an agent from finding another path and returning something that sounds authoritative. Without proper guardrails, agents take all context at face value, unable to distinguish good from bad. They can conflate similar concepts, confusing an app with a device, cross-wire descriptions, and confidently produce answers that are precisely wrong. The responsibility for governing that context and building the guardrails that prevent it sits entirely with the builder. That is not a limitation that goes away on its own. It is a design obligation.
What should the next generation of data engineers be preparing for now?
The next generation of data engineers is entering a world where the baseline job of producing data assets is getting commoditized. The differentiator is no longer who can build those artifacts but rather who can define the right spec in the first place. That is a much harder job, and it is the one worth preparing for.
In practical terms, that means owning semantics rather than scripts. What does “active user” actually mean in your business context? How do these entities relate? What are the golden structures that everything else should align behind? The ability to design a domain model that mirrors how the business actually thinks and operates will matter more than whether you can hand-craft the nth pipeline operator. Think of it as writing the markdown, a structured, precise expression of intent, that an agent then operationalizes. The quality of what the agent produces is a direct function of the quality of that spec. Treat data modelling as an act of meaning-making and not schema decoration.
The other half is evals. An agent can generate a metric, a dashboard, or a feature, but it cannot tell you on its own whether any of that is truly useful or aligned with the goals of the business. Being good at encoding goals as evals, defining what good looks like, how you would measure it, and what failure modes you are guarding against, will be one of the most important skills in an AI-saturated stack. It is the difference between the model works and the system is actually doing what we intended.
Underlying both is business fluency. If the last decade rewarded people who were very good at infrastructure and tooling, the next one will reward people who are very good at questions. Learn to think like the people you support. Understand how money flows through your company, what actually matters to your customers, how product and strategy decisions get made. Formal exposure to business thinking helps more than people expect. The goal is not to become a product manager but rather to develop the instinct to look at any dataset and identify levers, tradeoffs, and blind spots.
Near term, data engineers will be at the thick of things designing AI-ready systems and becoming AI-native themselves. Data engineers are the ones who understand the data well enough to do both. No other role can step in and own that, not a product manager, not a business analyst or an agent. The people who understand and own the data still matter, because they are also the ones responsible for ensuring that the experience of exploring data through agents is value adding for product leaders and stakeholders. Data democratization has always been the goal and AI is the most powerful lever we have ever had to achieve it, but only if the builders and domain experts collaborate together effectively.
Practically, lean into agents early. Use them to prototype quickly so you can spend more time on design. Stress-test your own understanding by having them explain or transform models you have built. Explore what-if questions at the edge of your intuition, then pull the promising ones back into rigorous evaluation. The people who will thrive are those who see agents as force multipliers on their judgment, not replacements for their labor.
If I had to compress it into a single paragraph, get very good at making meaning in messy systems. Learn the tools, but do not anchor your identity to them. Anchor it instead to business understanding, judgment, and the ability to turn fragmentation into something that both humans and machines can reason over with confidence.
Who should we spotlight next in the Data Engineer Things Community Newsletter, and why?
I would like to spotlight Tamar Phillips, my colleague at Meta, and someone whose perspective I think this community would find genuinely valuable.
Tamar has grown into senior leadership at Meta by building and leading large data engineering teams in the Integrity domain which is a good mix of cultural as it is technical. Dealing with spam, bullying and misinformation, integrity sits downstream of the entire Meta family of apps, which means data modelling is foundational. The privacy requirements are equally serious with sensitive data protection and compliance reporting to governments across multiple regulatory regimes. Getting that right, at scale sharpens your thinking in ways that are hard to replicate elsewhere.
More recently, Tamar has been driving AI readiness efforts for Integrity at Meta and leading the definition of new roles and archetypes for data engineers in an AI-native era, doing the actual legwork of figuring out what that transition looks like in practice.
Beyond the work itself, Tamar leads with empathy, domain expertise, and a clear eye on business impact and product value. He is exactly the kind of practitioner whose experience the data engineering community should hear more from.
Key Takeaways
Own Semantics, Not Scripts: As AI commoditizes pipeline creation, a data engineer’s value shifts from hand-crafting code to defining precise business logic. Success now depends on spec-driven development which entails structuring the metadata, taxonomies, and semantic models that serve as the foundational context AI agents need to reason over data accurately.
Measure Workflow Completion: Vanity metrics like tool usage or code generated mask the true question of quality. AI maturity can be measured by Workflow Completion (e.g., an AI agent autonomously detecting a pipeline failure, diagnosing the schema change, and opening a fixed PR) rather than mere Step Acceleration (e.g., using a copilot to write a regex string 30% faster).
Master "Evals" to Prevent Silent Failures: Traditional data quality tests fail when AI agents generate open-ended analytical queries or insights. Data engineers must master the craft of writing behavioral evaluations and regression suites to serve as guardrails, ensuring that agents don't confidently return wrong answers or cross-wire business logic when underlying infrastructure changes.
Community poll
💬 How to stay connected
ℹ️ About Data Engineer Things
Data Engineer Things (DET) is a global community built by data engineers for data engineers. Subscribe to the newsletter and follow us on LinkedIn to gain access to exclusive learning resources and networking opportunities, including articles, webinars, meetups, conferences, mentorship, and much more.