
Data Engineer Things Newsletter #22 (Aug 2025)
Adapt, Innovate, and Create Impact: Agentic Data Engineering, Data Modeling for Data Products, What Makes a Great Data Engineer, and more.




Hey All!
Great to connect with you through this newsletter, made possible by the incredible team working diligently behind the scenes. This month, I have taken the lead in introducing excellent content that will be helpful in your data engineering journey.
I am from Philadelphia, Home of the Liberty Bell and the boldest ideas. I have worked in India and the Netherlands before making a move to the US 12 years ago to do my Master’s. I have primarily worked in fintech industries and am currently working in utilities. In my free time, I read, play tennis, travel, and watch movies.
Data engineering is vast, and hundreds of tools and features are added each quarter. The fundamentals remain the same, and data engineering innovations have pushed the boundaries in how businesses efficiently utilize quality data. Knowing data engineering design patterns will help data engineers, irrespective of their level, to build high-quality data systems.
In this newsletter, I have included content based on where data engineering is heading, caveats in implementing changes, and modeling data products.
Read, gain insights, and make an impact!
- Ananda
📰 Data Pulse
AI: Ollama released their new app for macOS and Windows. The new app offers a user-friendly UI to download and chat with AI models, with support for file processing, multimodal capabilities, and adjustable context length.
AI: Agentic Data Engineering: Ascend.io – Agentic data engineering leverages AI agents with context metadata, logic, dependencies, and runtime behavior to build, manage, and optimize data pipelines efficiently and at scale. Ascend’s automation engine uses rich metadata to orchestrate pipelines by handling dependencies, initiating tasks, and enabling custom event-driven workflows.
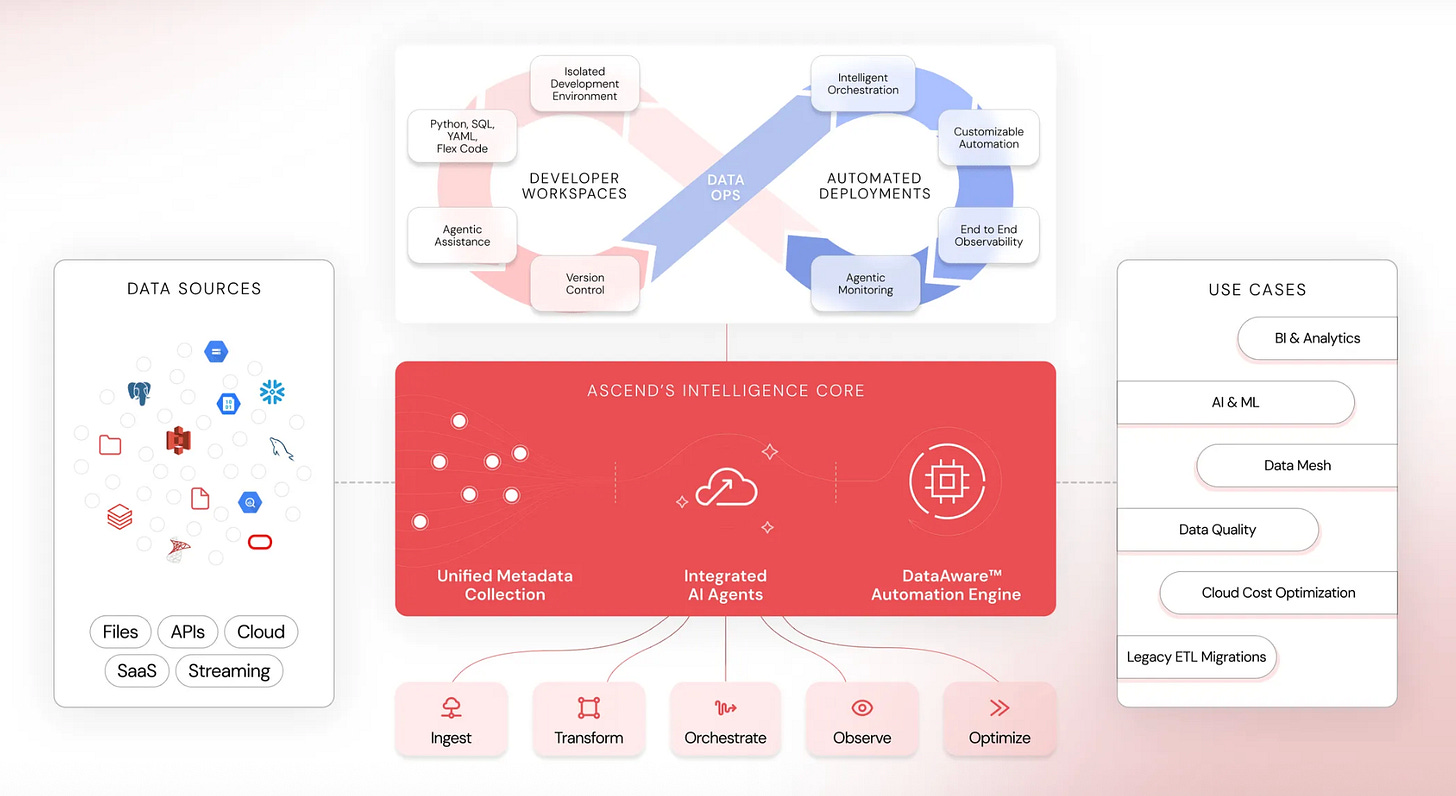
An overview of the Ascent platform (Source) AI: Lakeside AI enables organizations to deliver AI-ready data without needing a full migration to a lakehouse architecture. Through federated access, it helps to explore data in existing systems and brings only the most relevant datasets to the lakehouse when needed.
Data Analytics: SQLRooms is a React-based open-source framework that enables the building of data-centric applications using DuckDB. It allows quick, local analytics by directly interacting with file formats such as Parquet, Avro, and CSV through SQL. Ideal for dashboards, data exploration, and prototyping. A high-performance alternative to a database-backed app.
🗓 DET NYC Meetup on Sept 25

Attention, New Yorkers! You asked for it, and it's finally here: we are officially launching the DET NYC Meetup! Join the first NYC meetup on Sept 25th for an evening of learning, networking, and fun. Big thank you to Capital One for providing the venue and refreshments for the event.
When: 6:00 PM to 8:00 PM on Thursday, Sept 25th
Where: Capital One's NYC office
👉🏼 RSVP
To stay tuned for all future NYC events, make sure to join the meetup group (clicking the “Subscribe” button on the top right).
We are also looking for volunteers to help organize NYC meetups. Contact Sanchit Burkule if you want to be part of the team.
(🎤 Interested in speaking at our meetups or online webinars? Submit talk proposals here.)
🎬 Webinar: Improving Airflow Data Pipeline Reliability

At Astronomer, a team of just five data engineers manages 27,000 daily tasks, powering 18+ data products. In this webinar (11 am ET, Aug 21st), Maggie Stark, Staff Data Engineer at Astronomer, will share how her team reduced DAG failure rates by 81%:
Using Airflow Asset scheduling to prevent upstream dependency issues
Orchestrating cross-DAG dependencies with a Control DAG
Implementing centralized observability to monitor SLAs and debug faster
👉🏼 Sign up for the webinar HERE.
(This message is sponsored by Astronomer.)
🔖 Featured Read
Data Modeling for Data Products: A Practical Guide
Author: Mahdi Karabiben
Rethinking Data Modeling for the Age of Data Products
As data teams embrace product thinking and business-driven use cases, this article explores how to shift from rigid, monolithic models to adaptive, use-case-focused designs that evolve with the business. A data product is a curated, reliable dataset designed to serve a specific business purpose or use case.
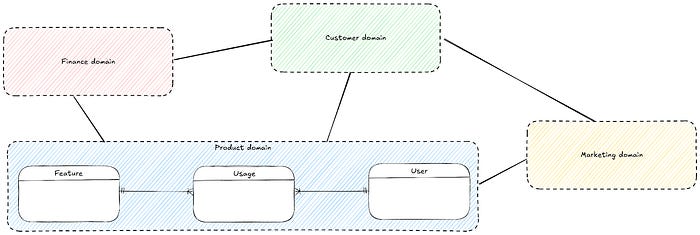
Approach to modeling data products:
Understand the “why” (core business needs and key business metrics)
Build the conceptual model (Business domains and how they relate to each other) and get the stakeholder buy-in.
Define the logical model at the domain level.
Adopt distributed ownership (Universal conceptual model with domain-specific modeling autonomy).
Data products and models must evolve continuously through incremental development.
Build a metric tree to connect business goals to underlying data components.
Create a semantic layer that maps business metrics to data, ensuring consistency, governance, and simplified access for users.
Use entity-centric modeling with enriched, denormalized tables to simplify queries and boost performance.
👉🏼 Read the full article HERE.
📚 Articles of the Month
DoorDash's realtime processing platform with Iceberg: Learn how DoorDash changed their architecture (Kafka → Flink → S3 → Snowpie → Snowflake) to include Iceberg (Kafka → Flink → Iceberg + S3) for their real-time processing platform (30 million messages per second) and saved 25-49% in storage costs, enabled concurrent writes, utilized hidden partitioning and increased the operational ability using query engines like Trino.
Database Sharding: Key Strategies: Sharding is a horizontal scaling technique used to distribute the load of a single database server across multiple machines, thereby spreading the data and query load evenly. This article explores the core concepts of database sharding, including its importance, how it functions, and the trade-offs involved.
Mussel - Airbnb’s Key-Value Store for Derived Data: An excellent article on how Airbnb uses Mussel to store derived data efficiently, achieving 99.9% availability, average read QPS (Queries per second) > 800k and write QPS > 35k, and average P95 read latency less than 8ms.
Speed Without Understanding - One of the Biggest Risks in Data Engineering: Rushing to implement changes without a complete understanding of the effect of changes is a huge risk in data engineering. Even small changes require thorough investigation and communication across teams, as this helps pinpoint unintended consequences.
(✍️ Interested in publishing articles on DET on Medium? Read submission guidelines here.)
✨ Share Your DET Story
We’re gathering testimonials from community members (like you!) to showcase the impact of the DET community and inspire others to join us. If the community has helped you learn, grow, or connect in any way, we’d love to hear your story! Fill out this short form to share your DET story.
🎨 Community Spotlight

Please introduce yourself briefly to the Data Engineer Things community!
Hi! I’m
, I am a data executive with over 20 years of experience. Today I’m an independent advisor. I help companies succeed with their data, and help individuals grow their careers.Throughout my career I’ve built data and analytics teams in various companies, ranging from scale-ups to bigger companies such as PayPal and Meta.
If your career were a Git repository, what would be the commit message for where you are right now?
Shachar was starting to get comfortable so we had to change something. This change may or may not work, we’ll find out..
I left what most people would consider the dream job (DE Director at Meta), with a salary I could have never dreamt of. I left A LOT of money on the table for something completely unknown. It was scary, nerve-wracking, and most people would say it was a crazy thing to do or even a mistake.
Today, two years later, I’m not looking back. Best decision of my life.
In one of your recent posts, you discuss the "career danger zone" for tech managers who lose technical skills while managing small teams. How can data professionals avoid falling into this trap?
In short – the “career danger zone” is the situation where you have a manager of a small team and not hands-on. Managers basically make themselves irrelevant this way, and when they look for another job they fail the technical interviews and realise they are not recruitable anymore.
The solution is simple:
Understand and recognise the danger zone
Unless you are a Director leading a 50+ people organisation – STAY HANDS-ON. Don’t lose your technical skills. You will become irrelevant.
What's the single best piece of career advice you've received that data engineers and aspiring data leaders should hear today?
Nobody cares what you do, and nobody cares how you do it. What they care about is how it’s impacting the business. If you understand the business and use your skills to drive business outcomes – you will win this game. Anything else is just a waste of everybody’s time.
Based on your experience across multiple industries, what skills do you believe will be most valuable for data professionals in the next 3-5 years?
Curiosity – asking questions and being in the details
Changeability – ability to take feedback, adapt, and change
Clarity – ability to understand and explain complex topics, and ask the right questions
Collaboration – ability to build relationships, influence, build communities, and get things done as a group
It’s pretty much guaranteed that through the next 3-5 years:
Our roles will change
Technologies will change
Our workplace and work culture will change
I strongly believe that people with these 4 skills will survive anything that comes their way.
What's one message you'd like to share with the Data Engineer Things community about creating impact through data leadership?
Data is the glue that connects every function in the organisation. Understand the business, learn how to lead with data, and your growth will be unlimited.
➡️ Learn More
If you want to learn more about building a successful career in Data Engineering, have a look at the following fireside chat with Shachar and Xinran.
💡 DE Tip of the Month
Data federation is the most effective way to gain seamless access to multiple data sources. The Federation doesn’t transfer data, but accesses it virtually from the source location. For quick prototyping or linking cloud and on-premises systems, this is useful. This solution works well when you want to limit data movement, create a single-window view, and desire timely information. However, this shouldn’t be used for high-volume or complex transformations.
Let us know what you like the most in the newsletter. See you next time!
Cheers,
ℹ️ About Data Engineer Things
Data Engineer Things (DET) is a global community built by data engineers for data engineers. Subscribe to the newsletter and follow us on LinkedIn to gain access to exclusive learning resources and networking opportunities, including articles, webinars, meetups, conferences, mentorship, and much more.