


Data Engineer Things Newsletter #21 (July 2025)
Embrace Change: Reimagined Newsletter, Git-for-Data, and Your Essential Data Pulse




Hey there,
Nice to meet you! You might wonder why Xinran isn't writing the intro this time - that's because we now have a motivated team behind the newsletter, and this month it's my pleasure to introduce you to it.
I'm writing to you from sunny California, where I've recently settled after a life-changing move from Germany to the US. Change has been the defining theme of my year - from navigating the relocation to watching my children experience their first American summer. Like in Data Engineering, sometimes the most challenging transformations yield the most rewarding results!
Speaking of change, you might notice our newsletter looks different this month. We've reimagined the format to deliver even more value to you, our readers. You might also see the theme of change in this month's featured read, where a Git-for-Data approach to managing change in data systems is discussed.
In this context, let me start the newsletter with a quote from a respected fellow Data Engineer:
Changing is scary, but so is staying the same.
Enjoy reading!
- Volker
📰 Data Pulse
AI: Anthropic published a new resource: Powered by Claude. A curated list of projects using Claude in production, a great source for AI inspiration.
AI: Google released Gemini CLI: your open-source AI agent.

Data Modeling: dbt Fusion engine public beta is now available on BigQuery.

Event streaming: Going beyond micro-batch. The new real-time mode in Apache Spark Structured Streaming provides p99 latencies less than 300 milliseconds for both stateless and stateful streaming processing.
Multimodal data formats: The rise of AI led to unprecedented needs for handling multimodal data at scale. Check out these up-and-coming open-source frameworks like Meta’s Nimble, Lance, and Daft.
Apache Iceberg v3: New features include deletion vectors, row lineage, semi-structured data, geospatial types, and interoperability with Delta Lake.
Full Apache Iceberg support in Unity Catalog: Read and write Managed Iceberg tables and use Unity Catalog to access and govern Iceberg tables in external catalogs
Declarative Pipelines: The declarative API for building robust data pipelines is now open-source and available for Apache Spark.
Lakebase: Serverless, Postgres-compatible OLTP database for the lakehouse.
Free Edition: Free Edition offers the same suite of tools that were previously limited to paying customers, allowing everyone to experiment and learn all the latest in data and AI technologies.
🗓 DET Seattle Meetup

Join the next Seattle Meetup for a deep dive into Apache Hudi and Lance—two open-source frameworks for building scalable lakehouse architectures.
When: 5:00 PM to 8:00 PM on Thursday, July 24
Where: Docusign Tower, 999 3rd Ave #1000, Seattle, WA 98104
Talk #1: Redefining Open Lakehouse Architecture with Apache Hudi 1.0, by Dipankar Mazumdar
Talk #2: Multimodal AI Lakehouse with Lance & LanceDB, by Jack Ye
👉🏼 RSVP
(🎤 Interested in speaking at our meetups or online webinars? Submit talk proposals here.)
🔖 Featured Read
In Git We Trust: Git for Data over Data Lakes
Author: Ciro Greco
Just as every software team adopted Git by 2010, every data team will adopt Git-for-Data by 2030.
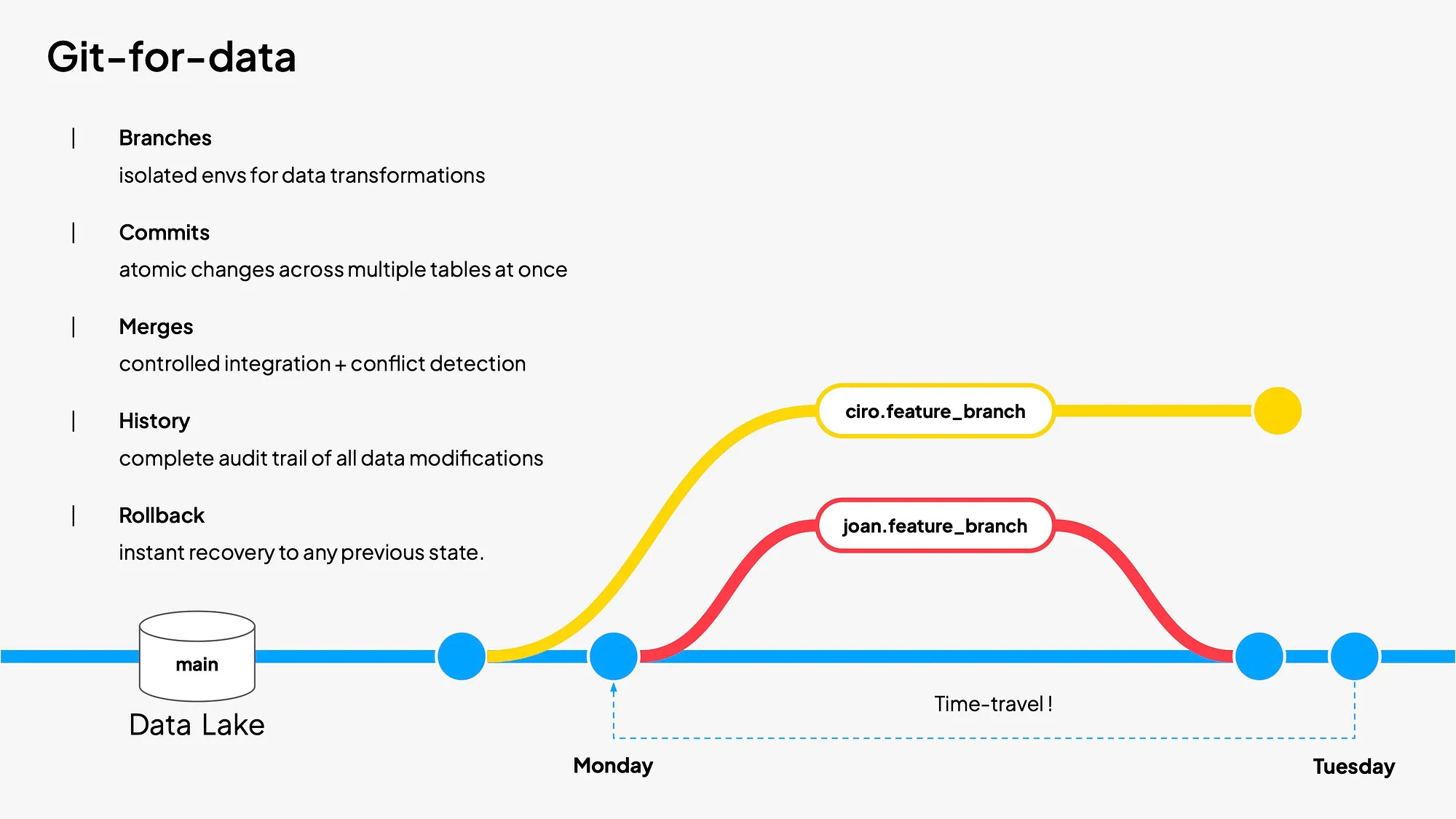
Data engineering is facing a crisis of reliability. While software developers enjoy the safety of Git's branches, commits, and rollbacks, data teams still work with loosely managed files with no built-in versioning. This creates three critical problems:
• Reproducibility nightmares
• Dangerous experimentation
• Manual everything
The Solution: Git Concepts for Data
Building on open table formats like Apache Iceberg and Delta Lake, the article envisions data workflows with:
• Branches to isolate experiments on real production data
• Commits to track multi-table changes as atomic units
• Merges to publish only after passing data quality checks
• Rollbacks to instantly undo bad pipeline runs
As AI becomes core to every product and data powers user-facing applications, we need software engineering-grade reliability for data operations. The convergence of AI adoption, real-time data applications, and Python as the data lingua franca is driving this inevitable shift.
The article showcases two use cases for Git-for-Data using Bauplan, a Pythonic data platform for transformation and AI workloads with built-in Git-for-Data capabilities.
👉🏼 Read the full article HERE.
📚 Articles of the Month
What is Apache Hive?: Lakehouses might be trending, but many companies still rely heavily on Apache Hive. Here's an excellent article that clearly explains Hive fundamentals.
Roblox’s Path to 2 Trillion Analytics Events a Day: Learn how Roblox built a real-time schema-based analytics pipeline, enabling them to handle over 2 trillion events daily with reduced latency and costs.
The 6 Most Common Customer Questions on Data Projects: A playbook on communication, expectation-setting, and collaborative processes between engineering teams and customers.
Embedding-Based Retrieval for Airbnb Search: Discover how Airbnb tackled the challenge of searching millions of listings by building a two-tower neural network that maps both queries and homes into numerical vectors. Their innovative approach to training data construction and serving infrastructure delivered booking improvements comparable to their largest ML ranking advancements in years.
(✍️ Interested in publishing articles on DET on Medium? Read submission guidelines here.)
🎨 Community Spotlight

Tell us about yourself and how you started to engage with the DET community.
I'm Volker, a Principal Data Engineer who has been working with data in the gaming industry for nearly 15 years. I started publishing articles with DET about a year ago, and now I'm happy to be contributing to the newsletter!
What's one Data Engineering resource (book, course, tool) you'd recommend that most engineers might not know about?
The Pragmatic Programmer by David Thomas and Andrew Hunt. It might seem a bit out of the box since it focuses on general software development rather than data engineering, but the lessons it teaches can be easily adopted. Its core concepts have become guiding principles throughout my career in tech.
If your data engineering career were a Git repository, what would be the commit message for where you are right now?
refactor(career): add documentation so others can learn from it
Tip: Use Semantic Commit Messages in your data engineering code changes to make your work more understandable for your team!
What's the best piece of career advice you've received that other Data Engineers might benefit from?
Ask the Spice Girls question: "So tell me what you want, what you really, really want."
This question forces you to uncover the motivation, the WHY, behind a stakeholder's request. Before you start working on any project, I recommend clarifying three things for yourself and your team: WHAT are we building? HOW are we building it? WHY are we building it? Understanding the why helps you design simpler, more valuable solutions and increases your visibility because you understand the business value behind the technical requirements.
💡 DE Tip of the Month
Always set alerts on pipeline failures! Silent failures quickly become holiday spoilers. I learned this the hard way by spending my 4th of July debugging pipelines. Don't let this happen to you. Monitor early, alert often. For example, set up alerts for missing or delayed data to catch jobs that fail quietly without throwing an error.
Let us know how you like the new newsletter format. See you next time!
Cheers,
ℹ️ About Data Engineer Things
Data Engineer Things (DET) is a global community built by data engineers for data engineers. Subscribe to the newsletter and follow us on LinkedIn to gain access to exclusive learning resources and networking opportunities, including articles, webinars, meetups, conferences, mentorship, and much more.
Love the newsletter! Btw, I can't select any options in the poll. Not sure if it's a bug.